Sparsh: Self-supervised Touch Representations
本笔记基于摘要 + 公开资料,未读全文。
一句话讲什么(TL;DR)
以前每个触觉任务都得从零教机器人。Sparsh 先让模型自己看大量触觉画面学一遍,再做具体任务只要少量例子就够。
类比:跟小孩先摸过几千次东西、再去学"握紧水杯"是一个道理。技术路线和 NLP 里 BERT、视觉里 DINO 一致——先大量自学,再小量微调,只是搬到了触觉这个长期缺数据的模态。
这是个什么场景 — 日常类比
想象你闭着眼睛在书包里摸钥匙。你怎么知道"这是钥匙不是口香糖"?不是有人事先告诉你"钥匙的触感叫做钥匙",而是你从小摸过水、毛巾、玻璃、橡皮、硬币几千次,大脑自动攒下了一套"触觉词汇"——滑/糙、软/硬、棱角/圆润。这套词汇本身没在做任何具体任务,但你之后所有靠手摸完成的事(系鞋带、找钥匙、握紧水杯不让它滑掉)都建立在它之上。
机器人现在做不到这一点。它的触觉传感器(比如 DIGIT、GelSight 这类视触觉传感器——本质是一块软胶 + 一个朝里看的摄像头,物体压上来胶变形、摄像头拍下形变图像)每秒能拍很多张图,但传统做法是"为某个任务(比如检测滑动)单独人工标注几千张图,训一个小 CNN",每换一个任务就得重来一遍,又贵又主观("这一帧到底算不算滑动?")。Sparsh 想做的事,就是把婴儿那段"没人教、纯靠摸"的成长过程搬给机器人:先让模型大量看触觉视频、自己学出"触觉词汇",再去做下游任务。

之前的人怎么做的 — 3-5 bullet
- 任务专用 CNN(task-specific):每个触觉任务(滑动检测、力估计、物体识别)单独标注、单独训一个小 CNN。换传感器 / 换任务都要重做。
- 多任务监督学习:把几个触觉任务凑一起多任务训练,但仍然依赖人工标注,规模上不去。
- 跨模态对齐(vision-touch contrastive):把触觉图和 RGB 图对齐(类似 CLIP 思路,参考 touch-vision-cross-modal),但要求成对数据,且对齐目标是视觉,不是触觉本身的结构。
- 手工特征:早期工作直接从 GelSight 图像提光流、面积变化,规则化但不可扩展。
- 仿真预训练:用仿真触觉数据(比如 TACTO)预训练,但 sim-to-real gap 在触觉上比视觉更严重(胶垫形变物理仿真不准)。
共同瓶颈:真实触觉数据有,但没人标;标注又贵又主观("这算滑动吗")。
这篇论文的关键想法
类比:图像领域已经有成熟的"先大量自学、再做具体任务"的菜谱(BERT/DINO/MAE 那一套),Sparsh 做的事就是把这本菜谱原封不动端到触觉的厨房:
- 不要标签:用遮挡补全、对比学习这类**代理任务(pretext task,意思是"装出来给模型练手的假任务")**从原始触觉图像里抠结构,绕开人工标注。
- 跨传感器统一:DIGIT、GelSight、GelSight Mini 等传感器拍出来的图看起来不一样,但底层物理(软胶形变 + 内部光学)是共通的——预训练时混着喂多种传感器的数据,backbone 学到的就是"传感器无关"的触觉表示。
- 下游接小头:预训练完,把 backbone 冻住或者轻微微调,下游任务(滑动检测、力估计…)只需少量标注 + 一个轻量 head(线性层或 MLP)就能追平甚至超过为它专门训的模型。
底层信念:触觉长期被"数据少 + 标不动"卡住,而 SSL 的核心红利就是"消化无标注数据"——按这个逻辑,触觉理应比视觉更吃 SSL 的红利。
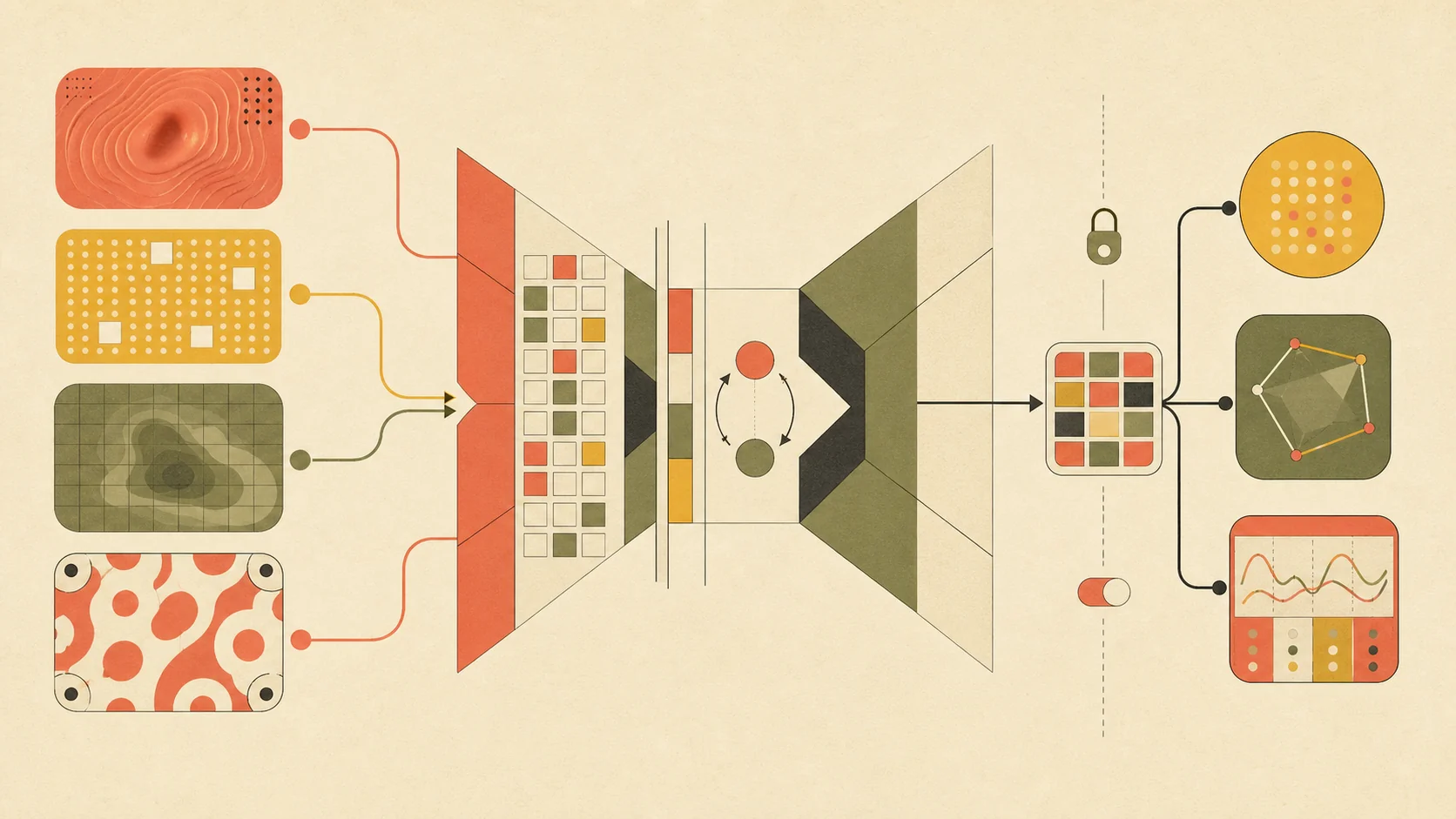
它怎么做的(方法)— 3-4 段
数据层:先囤食材。把多种视触觉传感器(DIGIT、GelSight 系列)拍下来的真实交互视频凑成一锅——跨任务、跨物体、跨操作者,机器人和人手压、抓、滑各种东西。规模"大于以往触觉数据集",具体小时数和帧数需读原文。数据全程不带任务标签,只是原始记录。
预训练目标:相当于给模型出几种不同的填空题练手。论文同时尝试了 MAE(Masked Autoencoder,掩码自编码)、DINO(自蒸馏,self-distillation)、JEPA(Joint Embedding Predictive Architecture,联合嵌入预测) 几套主流 SSL 范式。
等等,先慢一拍——这三种 pretext 题型分别在干什么?
- MAE:把触觉图遮掉一大半 patch,让模型补全被遮的部分(像挖空填空)。
- DINO:同一帧的两种视角拉近、不同帧推远(像让模型学"什么算同一个东西")。
- JEPA:不去补像素,而是在表示空间里预测未来帧(更像"理解趋势"而不是"画画")。
论文横向比这三种在下游任务上的表现,给出"哪种最适合触觉"的经验结论(具体排名需读原文)。
架构:backbone 用 ViT(Vision Transformer),因为它和 MAE/DINO/JEPA 配套成熟。输入是触觉图像(或一小段时间窗口的多帧),输出是一组 token 表示。可以理解成一个"专门看触觉图的眼睛"。
下游评测协议:像翻译完手册之后给学生考试。论文搭了一套触觉基准(TacBench 一类),覆盖力估计(force estimation)、滑动检测(slip detection)、姿态估计(pose estimation)、布料/物体属性识别等。下游评测时冻住 backbone 用 linear probe,或者少量数据微调,三方对比:Sparsh vs. 任务专用模型 vs. 从头训。
实验在做什么
核心实验回答 3 个问题:
- 预训练有用吗:在多个下游任务上,Sparsh 用 1/N 的标注数据是否能匹平甚至超过任务专用模型?预期结论:是,尤其在低数据(low-data regime)下优势最大。
- 哪种 SSL 目标最好:MAE / DINO / JEPA 谁赢?具体数字需读原文,但论文应给出一个推荐。
- 跨传感器迁移:在 DIGIT 上预训练的 backbone,迁到 GelSight 上 fine-tune 是否还有用?这是判断"通用触觉表示"是否真的通用的关键。
可能的次级实验:scaling(数据量 vs. 性能曲线)、可视化学到的注意力 / token 表示、与跨模态对齐方法的对比。
具体数字(提升百分比、绝对精度)需读原文。
你应该懂的几个新词 — 4-6 个
- 视触觉传感器(vision-based tactile sensor):核心结构是"一块软胶 + 朝里看的摄像头",物体压上来胶变形,摄像头记录形变的图像。代表:DIGIT(Meta 开源)、GelSight 系列。优势是空间分辨率高、便宜、量产容易;劣势是有延迟、易磨损。
- 自监督学习(SSL):不用人工标签,从数据自身构造预测任务。例:遮住一部分让模型补(MAE)、把同一物体两个视角拉近(对比学习)。
- MAE(Masked Autoencoder):何恺明团队 2021 提出,输入图遮 75% patch,模型预测被遮的内容。视觉 SSL 的代表方案之一。
- DINO:Facebook 2021 提出的自蒸馏 SSL,学生网络预测教师网络的输出,无需负样本。
- JEPA(Joint Embedding Predictive Architecture):LeCun 力推的 SSL 范式,不在像素空间预测,而在表示空间预测,认为更接近"理解"而非"生成"。
- 下游任务(downstream task):预训练完成后,用预训练模型解决的具体应用任务。例:滑动检测、力估计。
- linear probe:评测预训练表示质量的常用做法——冻住 backbone,只在最后接一个线性层训练,看精度多高。线性可分说明表示已经把任务相关的结构编码出来了。
它和其他论文什么关系
- vs. touch-vision-cross-modal:那篇是触觉-视觉跨模态对齐(CLIP 风格),需要成对数据;Sparsh 是纯触觉单模态 SSL,不需要配对。两者互补:Sparsh 学触觉本身的结构,cross-modal 学触觉和视觉的语义桥。
- vs. clip / [dino](视觉 SSL):Sparsh 是把视觉 SSL 的成功方案搬到触觉。技术上不是发明新方法,价值在于"证明这条路在触觉上也走得通 + 提供数据集和 benchmark"。
- vs. octo / openvla / pi0:这些是机器人 policy 大模型,输入是 RGB + 本体感知,几乎都没用触觉。Sparsh 提供了一个可以接到这类 policy 上的触觉 encoder——未来 VLA + 触觉的方向上,Sparsh 是一个可能的 plug-in。
- vs. dexcap / dexmv:那些是高质量灵巧操作数据采集,触觉是其中一路信号。Sparsh 关注的是"有了数据后怎么把触觉表示学好",是下游环节。
- 历史脉络:视觉先有 ImageNet 监督预训练 → 然后 SimCLR/MoCo/MAE/DINO 自监督预训练 → 触觉这条线相对滞后约 5 年,Sparsh 算是触觉版的"MAE 时刻"。
我建议这样读 — 3-4 步
- 先读 abstract + intro 的 3 张图:搞清楚"输入什么数据、输出什么表示、下游评测的几个任务长什么样"。如果这三件事没在脑子里有画面,看方法会糊。
- 跳到实验的主表:直接看 Sparsh vs. 从头训 vs. 任务专用模型在几个任务上的对比,记住 1-2 个具体数字(比如"低数据下 +X%"),后面好引用。
- 回看方法节:重点看预训练目标到底用了哪几种、为什么选这几种、它们在触觉上和在视觉上有什么不同(比如帧的时序怎么处理)。
- 如果时间够:看 ablation——尤其是"跨传感器迁移"那一组,这是判断"是否真的通用"的关键,也是这篇论文最容易被后续工作扩展的地方。
读完应该能回答:Sparsh 的预训练目标是什么 / 用了多少数据 / 在哪个任务上提升最大 / 跨传感器是否真的迁移得好。
为什么值得读
- 方向意义:触觉是机器人多模态拼图里长期缺位的一块(视觉、语言、本体感知都已经有大模型,触觉还在 task-specific 阶段)。Sparsh 是把"基础模型范式"引入触觉的标志性工作之一。
- 可复用性:Meta 开源了 DIGIT 传感器和(预期)Sparsh 模型权重,下游研究者可以直接用,不必自己从头训。这意味着触觉研究的入门门槛在快速降低。
- 方法论启发:即使你不做触觉,这篇论文也是"如何把成熟范式(视觉 SSL)搬到新模态"的一个干净案例——选数据、选 pretext、建 benchmark、做跨设备迁移,每一步都是可复用的方法论。
- 对 VLA / policy 大模型的接口:未来的机器人 policy 几乎一定会接触觉。Sparsh 这类 encoder 是 VLA 接触觉的标准接口候选。提前理解它,能让你看后续 VLA + 触觉的论文时不卡。
- 诚实提醒:这篇是 representation learning 论文,不是端到端策略论文。它本身不会让机器人变得"更会抓",而是给"让机器人更会抓"的下游工作提供一块更好的零件。判断它的价值要看下游 adoption,而不是看它自己 demo 多炫。
◼
引用本笔记 / Cite this note
@online{eai_sparsh_2026,
title = {(readable note) Sparsh: Self-supervised Touch Representations},
author = {Zhou, Jason},
year = {2026},
note = {Note on a 2024 paper},
howpublished = {\url{https://estelledc.github.io/embodied-ai-reading-station/papers/sparsh/}},
organization = {Embodied AI Reading Station}
}
All 156 papers (full index)
- 1. LLaVA: Visual Instruction Tuning
- 2. 3DShape2VecSet: 3D Shape Representation for Diffusion Models
- 3. SayCan: Do As I Can, Not As I Say
- 4. OpenVLA: An Open-Source Vision-Language-Action Model
- 5. VLAS: VLA Model With Speech Instructions
- 6. MLA: Multisensory Language-Action Model
- 7. Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control
- 8. CartoRadar: RF-Based 3D SLAM Rivaling Vision Approaches
- 9. mmCLIP: Boosting mmWave-based Zero-shot HAR via Signal-Text Alignment
- 10. mmNorm: Non-Line-of-Sight 3D Object Reconstruction via mmWave Surface Normal Estimation
- 11. Proactive Hearing Assistants that Isolate Egocentric Conversations
- 12. NeuralAids: Wireless Hearables With Programmable Speech AI Accelerators
- 13. Creating speech zones with self-distributing acoustic swarms
- 14. Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation
- 15. SoundStream: An End-to-End Neural Audio Codec
- 16. AudioLM
- 17. Conformer
- 18. Dual-path RNN
- 19. EnCodec
- 20. Meta-StyleSpeech
- 21. MusicLM
- 22. Robust Speech Recognition via Large-Scale Weak Supervision
- 23. SeamlessM4T
- 24. Stable Audio
- 25. Universal Source Separation with Weakly Labelled Data
- 26. Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning
- 27. RLBench: The Robot Learning Benchmark & Learning Environment
- 28. robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
- 29. BridgeData V2
- 30. CALVIN
- 31. LIBERO
- 32. RH20T
- 33. What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
- 34. DROID
- 35. Open X-Embodiment
- 36. RoboCasa
- 37. SimplerEnv
- 38. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
- 39. 3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
- 40. Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation
- 41. EquiBot: SIM(3)-Equivariant Diffusion Policy
- 42. DiT-Policy
- 43. Diffusion Policy Policy Optimization (DPPO)
- 44. Affordance-based Robot Manipulation with Flow Matching
- 45. FlowPolicy: 3D Flow-based Policy via Consistency Flow Matching
- 46. FAST: Efficient Action Tokenization for VLA
- 47. pi_0: Vision-Language-Action Flow Model
- 48. pi_0.5: VLA with Open-World Generalization
- 49. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
- 50. Generative Adversarial Imitation Learning
- 51. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (ACT/ALOHA)
- 52. AnyTeleop
- 53. Behavior Transformers: Cloning k Modes with One Stone
- 54. Implicit Behavioral Cloning
- 55. RoboCat
- 56. ALOHA 2
- 57. DexCap
- 58. HumanPlus
- 59. Generalizable Humanoid Manipulation with 3D Diffusion Policies (iDP3)
- 60. Mobile ALOHA
- 61. SmolVLA
- 62. Universal Manipulation Interface
- 63. Behavior Generation with Latent Actions (VQ-BeT)
- 64. ImageBind: One Embedding Space To Bind Them All
- 65. Connecting Touch and Vision via Cross-Modal Prediction
- 66. AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
- 67. AudioPaLM
- 68. FROMAGe: Grounding LLMs to Images
- 69. OneLLM
- 70. X-VLM: Multi-Grained Vision Language Pre-Training
- 71. Tactile Beyond Pixels (Sparsh-X)
- 72. Sparsh: Self-supervised Touch Representations
- 73. Tactile-VLA
- 74. TLA: Tactile-Language-Action
- 75. Code as Policies: Language Model Programs for Embodied Control
- 76. Inner Monologue: Embodied Reasoning through Planning with Language Models
- 77. LLM+P: Empowering LLMs with Optimal Planning
- 78. PaLM-E: An Embodied Multimodal Language Model
- 79. ProgPrompt
- 80. ChatGPT for Robotics
- 81. GenSim
- 82. RoboFlamingo
- 83. Tree-Planner
- 84. VoxPoser
- 85. See Through Smoke: Robust Indoor Mapping with Low-cost mmWave Radar
- 86. Can WiFi Estimate Person Pose?
- 87. 3DRIMR: 3D Reconstruction and Imaging via mmWave Radar based on Deep Learning
- 88. milliEgo: Single-chip mmWave Radar Aided Egomotion Estimation via Deep Sensor Fusion
- 89. High Resolution Point Clouds from mmWave Radar
- 90. RadarSLAM: Radar based Large-Scale SLAM in All Weathers
- 91. Through-Wall Pose Imaging in Real-Time with a Many-to-Many Encoder/Decoder Paradigm
- 92. RFMask: A Simple Baseline for Human Silhouette Segmentation with Radio Signals
- 93. RFPose-OT: RF-Based 3D Human Pose Estimation via Optimal Transport Theory
- 94. Argus: Multi-View Egocentric Human Mesh Reconstruction Based on Stripped-Down Wearable mmWave Add-on
- 95. Diffusion Model is a Good Pose Estimator from 3D RF-Vision
- 96. Enabling Visual Recognition at Radio Frequency (PanoRadar)
- 97. Wave-Former: Through-Occlusion 3D Reconstruction via Wireless Shape Completion
- 98. Habitat: A Platform for Embodied AI Research
- 99. Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
- 100. DexMV
- 101. Habitat 2.0
- 102. ManiSkill
- 103. ProcTHOR
- 104. SAPIEN: A SimulAted Part-based Interactive ENvironment
- 105. BEHAVIOR-1K
- 106. Habitat 3.0
- 107. Isaac Lab
- 108. MuJoCo Playground
- 109. RT-1: Robotics Transformer for Real-World Control at Scale
- 110. 3D Diffusion Policy (DP3)
- 111. Octo: An Open-Source Generalist Robot Policy
- 112. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- 113. RT-Trajectory: Robotic Task Generalization via Hindsight Trajectory Sketches
- 114. 3D-VLA
- 115. DexVLA
- 116. GR-2: Generative Video-Language-Action Model
- 117. OpenHelix
- 118. OpenVLA-OFT
- 119. RDT-1B: Diffusion Foundation Model for Bimanual Manipulation
- 120. RoboMamba
- 121. SpatialVLA
- 122. TinyVLA
- 123. TraceVLA: Visual Trace Prompting
- 124. Learning Transferable Visual Models From Natural Language Supervision
- 125. Flamingo: a Visual Language Model for Few-Shot Learning
- 126. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 127. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- 128. DeepSeek-VL: Towards Real-World Vision-Language Understanding
- 129. EVA-CLIP: Improved Training Techniques for CLIP at Scale
- 130. FILIP: Fine-grained Interactive Language-Image Pre-Training
- 131. Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
- 132. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
- 133. Improved Baselines with Visual Instruction Tuning
- 134. OBELICS
- 135. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
- 136. Sigmoid Loss for Language Image Pre-Training
- 137. What matters when building vision-language models?
- 138. Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
- 139. The Llama 3 Herd of Models
- 140. LLaVA-NeXT-Interleave
- 141. LLaVA-OneVision: Easy Visual Task Transfer
- 142. Long-CLIP: Unlocking the Long-Text Capability of CLIP
- 143. Pixtral 12B
- 144. Dream to Control: Learning Behaviors by Latent Imagination
- 145. World Models
- 146. DayDreamer
- 147. Mastering Atari with Discrete World Models
- 148. Dreamer V3: Mastering Diverse Domains through World Models
- 149. Transformers are Sample-Efficient World Models
- 150. TWM: Transformer-based World Models
- 151. 1X World Model Challenge
- 152. Cosmos World Foundation Model Platform
- 153. GAIA-1
- 154. Genie: Generative Interactive Environments
- 155. Navigation World Models
- 156. UniSim