Through-Wall Pose Imaging in Real-Time with a Many-to-Many Encoder/Decoder Paradigm
这是一份给"完全没接触过 AI、也没碰过雷达"的读者看的精读笔记。所有物理和公式都翻成人话,类比都来自日常生活。
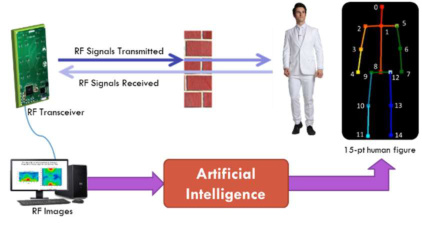
一句话讲什么(TL;DR)
一个 Wi-Fi 小盒子隔着墙照过去,就能画出屋里人的骨架动画——摄像头当老师,电波当学生,学一遍就会了。
更具体一点:
- 输入:一个商用雷达(Walabot Developer,几百美元)发出去的电波被人体反射回来后形成的 3D 强度场。
- 输出:屋内每个人的 15 关节点骨架,每秒约 18 帧,可以连成视频。
- 关键技巧:1)用普通摄像头同步录像,跑 OpenPose 自动生成"标准答案"训练雷达模型;2)模型用 CNN 提空间特征 + RPN 找多人 + LSTM 串时间,因为单帧雷达图看不全人。
- 应用:火场搜救、医院老人监护、军警侦查——所有"看不见但需要看见"的场景。
所以这一节是想说:这篇论文造了一个"穿墙人形雷达",输出的不是黑白噪点,是 15 个关节点连起来的骨架视频。
这是个什么场景
你玩过捉迷藏吗?躲在门后、桌子底下,外面的人喊半天也找不到。现在把这事换个严肃版本:一栋房子着火了,烟把整层楼糊得跟黑墙一样。消防员站在门口,知道楼上"可能还有人",但他不知道这个人在哪个房间、是站是躺、有没有动。每多 1 分钟搜,存活率就掉一截。普通摄像头被烟挡死,红外摄像头也一样。论文里给了一个吓人的数字:1994-2013 年间全球 6873 起自然灾害造成 135 万人死亡——其中相当一部分本来是有机会被"看见"的。
再换个温和点的场景。你家爷爷一个人住,你想知道他半夜起床上厕所有没有摔倒,但你不可能在他卧室装摄像头——老人会觉得"你天天盯着我洗澡换衣服?"。
这两件事看起来八竿子打不着,但卡住的是同一个问题:我想知道屋里那个人是什么姿势,但:
- 看不见——烟、墙、家具挡在中间;
- 不能让他穿东西——昏迷的人没法自己戴手环,老人也懒得戴。
那有没有一种"光"能穿过墙又对人没害?可见光波长只有几百纳米,撞到墙就被吃掉了。X 光倒是能穿,但有辐射,天天照人会出事。长波广播能穿,但波长太长,画不出胳膊腿这种小细节。唯一刚刚好的是 Wi-Fi 频段电波(3-10 GHz,波长 5 厘米左右)——它能穿木板、石膏板、砖墙,能量低到对人无害,而人的皮肤又恰好会把它反射回去一部分。这就给了"用电波当眼睛"的物理可能性。
这篇 2019 年的论文要做的事就一句话:装一个发 Wi-Fi 频段电波的小天线阵列,让它代替摄像头,画出屋里人的骨架。
所以这一节是想说:这篇论文要解决的是"有人在但你看不见"的盲区——靠电波穿墙,把人形画出来。

之前的人怎么做的,为什么不够好
- 戴传感器方案(如 Xsens 商用产品 [37]):让人穿一身惯性测量单元(IMU),靠陀螺仪重建姿态。问题:搜救场景里被困者根本没穿;老人监护场景里没人愿意天天戴;军警侦查里更不可能让目标穿。这是个经典的"系统能用但不适用"的尴尬。
- RGB 摄像头 + OpenPose(论文 [20]):精度高,但光线一挡就废,烟、墙、家具全是 boss。这条路线的极限就是"在能看见的地方"——本质上和人眼一样的限制。
- 毫米波雷达(100 GHz):分辨率够细,但穿不过墙——波长太短了。汽车自动驾驶用毫米波是因为没人会要求汽车看穿前面那辆车。
- Wi-Fi 定位(早期 RF 工作 [39][40][41][42][43]):能告诉你"屋里有人",但只是一个点(甚至需要被定位者带 Wi-Fi 设备),画不出姿势。这条路适合"找人"不适合"看人"。
- MIT 的 RF-Pose(CVPR 2018,论文 [35]):是这条路线的前辈,能画骨架,但他们用 3D 卷积处理时间序列,作者认为3D 卷积聚合时空信息不如 CNN+LSTM(引用 Zuo et al. [36] 的对比),而且训练流程没专门针对穿墙场景设计——他们的训练数据基本是"看得见"的,到真正穿墙时就外推。
所以这一节是想说:要么戴设备不现实,要么看不见墙后头,要么能穿墙但画不细,要么穿墙但训练分布不对——这篇论文想把"穿墙 + 高精度 + 实时 + 训练分布对齐"四件事凑齐。
这篇论文的新想法
类比:拼乐高时一次抓一把拼不出全貌,连着抓几把、把每次看到的不同零件累积起来,整体才出来。电波看人也一样:一瞬间只能照到半个人,连着看几秒才能拼出完整骨架。
所以核心想法两条:(1) 不要看一帧画一帧(拍照),要看一段画一段(录视频);(2) 用摄像头当老师、电波当学生——电波没法人工标注,但摄像头能自动画好骨架让电波模型照着学。
落地起了个名字叫 "Many-to-Many Encoder/Decoder"(多对多编解码器):
- 多帧输入(many in):连续若干帧雷达热图一起进网络;
- 多帧输出(many out):每一帧都解码出对应的骨架;
- 中间靠 LSTM(会"记住前几秒"的网络)把过去的零碎反射累积起来。
对比之下,传统 RGB 姿态估计是 one-to-one:一张图进、一副骨架出。差别本质来自信息密度:RGB 一张图就饱和,RF 一张图永远不够,必须时序拼接。
它分几步做的(方法)
整个流水线分 5 步:装传感器 → 收数据 → 把雷达数据预处理成图 → 喂进深度学习模型 → 输出骨架。我挑 5 个最关键的子模块讲。下面每节会先打个比方让你抓住直觉,再讲它具体在算什么,最后说为什么这步必不可少。
1. 同时录制电波和摄像头:Co-Located 数据采集
类比:教小孩认水果时,你一手拿苹果(让他看到),一手让他摸(让他感受重量、形状)。视觉和触觉同步很重要——不能让他看苹果摸橙子。
它在干什么:把一个 Walabot 雷达和一个 Logitech C920 USB 摄像头绑在同一个三脚架上,对着同一个方向。两路数据时间戳对齐到 5 毫秒以内。摄像头分辨率降到 640×480 节省存储。这样每一帧 RGB 图和那一刻的电波数据讲的是同一件事——同一时刻、同一视角、同一组人。
FMCW:Frequency-Modulated Continuous Wave,频率调制连续波。雷达发出去的不是固定频率的"嘀",而是从 3.3 GHz 一直滑到 10 GHz 的"嘀——"。靠收到的回波频率比发出去时慢了多少(Δf),反推出反射点离我们多远。 Walabot:以色列一家公司做的开发板雷达,Wi-Fi 频段,发射功率约 100 皮瓦——是 Wi-Fi 的千分之一,对人无害。
为什么这步有用:因为电波的标签没法手工画——你不可能盯着一团雷达回波热图标 15 个关节。但你可以让摄像头自动生成标签,电波模型只要学着"对齐"就行。这就是后面师生范式的物理基础。如果两路传感器没对齐到 5 毫秒以内,老师批的卷子和学生答的卷子讲的都不是同一道题,整个监督就崩了。
所以这一节是想说:把雷达和摄像头粘在一起同步录,是为了让"看不见的电波"有"看得见的真值"可以学。
2. 把 3D 点云压成两张 2D 热图:降维预处理
类比:你在一个透明立方体盒子里放了一只猫,从正面看是一个猫的轮廓,从上面看是另一个猫的轮廓。两张 2D 投影合起来,你大概能脑补出猫的 3D 位置——比直接处理整个立方体的体素便宜多了。这跟医学影像里的 CT 重建逻辑相反:CT 是从多角度 2D 投影还原 3D;这里是从已有的 3D 数据投影出多个 2D 让模型处理。
它在干什么:雷达原始输出是球坐标 (θ, φ, r) 下的 3D 强度场——θ 是水平角,φ 是俯仰角,r 是距离。先用三个公式(论文 Equation 4:x=r·sin θ,y=r·cos θ·sin φ,z=r·cos θ·cos φ)转成笛卡儿坐标 (x, y, z),再沿两个方向求和:
- 把 y 方向(深度)压扁,得到一张 垂直热图(x-z 平面,正面视角);
- 把 z 方向(高度)压扁,得到一张 水平热图(x-y 平面,俯视)。
Heatmap(热图):每个像素的亮度代表这一格里反射回来的电波能量。亮的地方说明"这里有东西反射"。
为什么这步有用:3D 点云直接喂神经网络又慢又贵,实时性做不到。两张 2D 图保留了关键空间信息,计算量降了一个数量级——这是后面能做到 5Hz 实时的前提。代价是损失了一点深度细节,但对画 15 个关节来说足够了——你不需要知道手指的厚度,只需要知道手在哪。
所以这一节是想说:把 3D 雷达数据"拍扁"成两张 2D 图,是为了又快又不丢关键信息。
3. 师生跨模态监督:OpenPose 当老师,雷达模型当学生
类比:费曼学习法——你想懂一个东西,就找一个已经懂的人讲给你听,然后你照着复述。RGB 摄像头+OpenPose 是已经成熟的"老师",知道什么叫"人的骨架";雷达模型是"刚转学过来的学生",看的是另一种"语言"(电波),但要回答同一道题(15 个关节坐标)。论文摘要里特意提到这是受费曼学习法启发——通过"教别人"或"被同一题目以不同形式考"来加深理解。
它在干什么:
- 摄像头那一路图片喂给 OpenPose(CMU 在 CVPR 2017 提出的 RGB 姿态估计模型),生成 15 个关节的 (x, y) 坐标——这就是"老师批改的标准答案"。
- 雷达那一路热图喂给"学生模型"(CNN+RPN+LSTM),让它输出自己的 15 个关节坐标。
- 比较两套答案的差距,反向传播更新学生模型。
每个训练样本本质是一个 5 通道张量:2 个雷达热图通道 + 3 个 RGB 通道,只有雷达通道进学生模型,RGB 只用来生成标签。形式上看起来"输入是 5 通道"但实际上 RGB 通道只跟损失计算有关,不参与梯度回传到学生网络。
OpenPose:CMU 在 2017 年做的实时多人 2D 姿态估计模型,本论文用它的 BODY-15 关键点定义。 Cross-Modal Supervision(跨模态监督):监督信号从"另一种数据形式"(RGB)来,而不是从人工标注来。
为什么这步有用:解决了"电波数据没法人工标注"的死结。只要老师在场(光线好的时候录),学生就能学;学完之后学生自己上岗——后面真到墙后或者烟里,就只用电波。这种"训练用双模态、推理用单模态"的范式叫特权信息(privileged information)学习——老师在训练时拥有学生看不到的信息(清晰 RGB),训练完老师就退场。这是这条研究线(包括前辈 RF-Pose)的核心套路。
所以这一节是想说:用一个现成的"看图模型"当家教,让"看电波的模型"在不用人手工标的情况下学会画骨架。
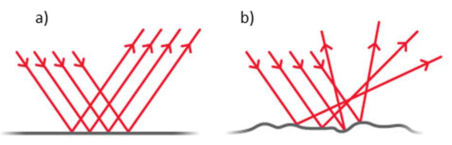
4. CNN + RPN + LSTM 三件套:解决"半透明、多人、时间断续"
类比:
- CNN(卷积神经网络) 像是你眯眼看一张糊掉的热图,能认出"这块亮斑像个人头"——它学会了"什么样的局部能量分布对应什么部位"。
- RPN(区域候选网络) 像是你画框圈出"这是甲、那是乙",处理多人场景——它学会了"哪些热斑应该被分组在一起当成一个人"。
- LSTM(长短期记忆网络) 像是你看连续几秒的视频回忆——"刚才那条腿动了一下,所以胳膊在那边"——它学会了"当前帧没看见但过去看见过的部位应该出现在哪"。
三个模块的分工很清楚:CNN 解决"是什么"(特征提取)、RPN 解决"在哪里 + 谁是谁"(多人定位)、LSTM 解决"什么时候"(时间累积)。这种分而治之是 2017-2019 年视觉时序任务的主流模式。
它在干什么:
- 雷达热图先过 DarkNet-53(一个 ResNet 变种,YOLOv3 的骨干网络),提取空间特征;
- RPN 像 YOLOv3 一样输出最多 P 个人的候选框,每个人编码成一个 445 维向量(4 个框坐标 + 21×21 的特征图压平);
- 这些向量按时间排队送进 LSTM,让它综合"过去几秒"的信息再输出当前帧的关节;
- 最后两层全连接把 LSTM 隐藏状态变成 (x, y) 像素坐标。
ResNet(残差网络):让深层网络好训的关键技巧——加一条"跳过中间层"的快捷连接,梯度不容易消失。 RPN(Region Proposal Network):从一张特征图里生成"可能有物体的方框",源自 Faster R-CNN(论文 [25])。 LSTM(Long Short-Term Memory):RNN 的一种,靠输入门、输出门、遗忘门避免梯度消失,能记住长达几十步前的信息。
论文还在 RPN 损失里加了一个Siamese 风格的"身份一致性"项:让同一个人在前后帧的 21×21 特征图保持相似,不同人之间则要远离。这相当于教模型"记住每个人长啥样",不会前一帧把甲认成乙、后一帧又认错。
为什么这步有用:这是论文最核心的"many-to-many"思想。RF 信号有个物理毛病叫镜面反射(specularity)——5cm 波长下,人体表面对电波来说是"镜子"而不是"磨砂面",只有近似垂直入射的部分才会反射回天线。所以任何一帧雷达图都只能看到部分肢体,胳膊看到了腿可能就丢了。
但人在动,所以下一帧反射回来的部分不一样。LSTM 的工作就是把不同时刻零散的反射拼起来——单帧拼不出全身,几秒钟拼起来就能。这跟优化里的"用时间换空间"很像:单帧空间信息不够,那就在时间维度上多攒一会儿。
所以这一节是想说:雷达单帧只看得到半个人,但靠 LSTM 把几秒钟的"半个"拼起来,就能拼出完整骨架。
补充一个细节:这套架构跟 OpenPose 的"先检测再连骨架"思路不同,本文是 每个人独立预测 15 个关节坐标——RPN 输出 P 个候选框,每个框对应一个人的 21×21 特征图,LSTM 拼时序信息后两层 MLP 直接吐出 (x, y) 像素。这个设计避免了"骨架连错"问题(A 的胳膊连到 B 的肩上),代价是对 RPN 的多人区分能力要求高。
5. 物理驱动的训练数据增强:故意让雷达"看不见"
类比:你想训练一个会读潦草字迹的 OCR 模型,光给它工整的印刷字训练没用——得故意混入手写、有污渍、被折过的。再换一个类比:飞行员模拟器训练里会刻意制造极端天气场景,让飞行员在真实事故发生前就练过类似的题。
它在干什么:用一个只挡电波不挡摄像头的支架,在录数据的时候插入木板、砖、石膏板、混凝土、塑料、纸板、绝缘棉、油毡、地毯、雾、树叶共 11 种障碍物。结果就是:摄像头照样看到人(OpenPose 还能给出标签),但雷达接收到的信号已经被障碍物衰减/扭曲。这是一个相当聪明的工程 hack——传统做法是真的隔着墙录,但那样就没法用 RGB 当老师了。这套支架本质上是"对一个模态透明、对另一个模态不透明"的滤镜。
总共录了 75,000 对 {RF, RGB} 样本,分布在家、学校、健身房、图书馆等多场景。按 75/5/20 切分成训练/验证/测试集。还故意录了一些没人的"对抗样本"——里面可能有看起来像人的电波模式(柜子、椅子、墙角),用来防止模型瞎报"幽灵人"。这种"没有人也要让模型说没有人"的训练数据,相当于人脸识别里的"否定样本"。
另外作者引入了一个新的损失函数 L_cls(论文 Equation 12),核心是把传统交叉熵乘上一个 e 的指数项,参数是预测点和真值点的像素距离 δ。离得越远惩罚越重,离得近就不太关心——这避免了一个常见问题:模型为了把每个像素分得"完美",反而过拟合训练集的细节。同时它还乘了 OpenPose 老师对该关节的置信度,老师没把握的关节学生不用学得太死。
最后这三个损失(区域候选、跟踪、分类)按 4:3:4 的比例加权(公式 14:L = L_RPN + 0.75·L_track + L_cls),用 Adam 一起优化。三个损失互相牵制——任何一个都不能压倒另外两个,否则模型会偏科:只优化 RPN 会让框很准但姿态乱,只优化分类会让多人混淆。
为什么这步有用:之前的工作不专门针对穿墙训练,模型只是"在普通场景下学过一点",到墙后就掉链子。这里显式让模型在墙后场景里训练,相当于直接练了"穿墙这道题"。配上对距离敏感的新损失函数,能进一步抑制过拟合。
所以这一节是想说:要让模型穿墙,你训练时就得让它真的隔着墙学;再配一个对距离敏感的损失,模型才不会过拟合。
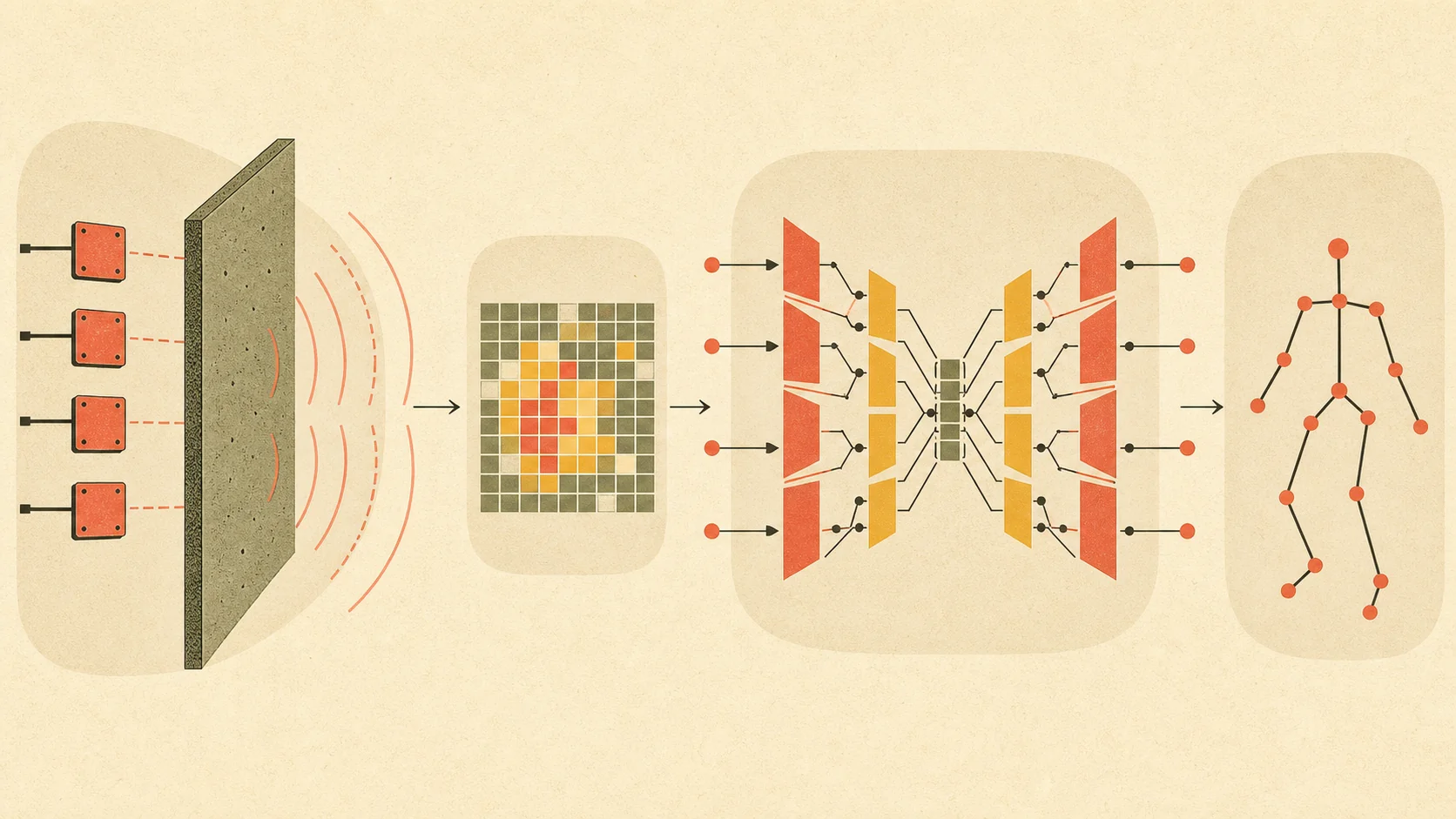
关键数字(What works)
- 0.056 秒/帧(约 18 fps,作者保守称 5Hz 实时流)。意味着:装在搜救设备上,消防员能看到准实时的骨架视频而不是几秒一刷的快照。剩下的 0.15 秒留给网络传输——这是为远程指挥设计的延迟预算。
- 75,000 训练样本,覆盖 11 种障碍物(木、砖、石膏、混凝土、塑料、纸板、绝缘棉、油毡、地毯、雾、树叶)。对比同类早期 RF 工作通常只有几千样本,这个数据量在 2019 年算很可观——也是模型对"奇怪墙壁"鲁棒的来源。覆盖了家庭、学校、健身房、图书馆四种场景,意味着模型不会被某一种墙的回波模式主导。
- 肩、髋关节在 KS=0.75(严格匹配)下准确率 72%-84%。对比手腕、脚踝的 30%-40%。这意味着身体核心位置追得很准,末梢肢体常常飘——直接对应"末梢反射面积小、特异性高"的物理事实。在搜救场景这个分布刚好够用——你不需要知道被困者的手指姿势,知道躯干位置和大致姿态就能定位。
- 穿墙场景准确率与无遮挡场景几乎持平(多数关节差距在 5-15 个百分点内)。这意味着论文最大的卖点真的成立了:墙不会显著降级模型,主要瓶颈是肢体本身的镜面反射。这也是为什么作者敢说这是"通用穿墙姿态估计"而不是"在透明环境里的姿态估计"。
- Many-to-many 比 frame-by-frame 全面胜出(论文 Figure 9)。这是验证 LSTM 这个设计选择的核心实验:去掉 LSTM 单看每一帧,准确率显著下降——证明"靠时间序列拼出完整骨架"不是空想。这也是 ablation study 中最有说服力的一个对比。
- 在低 KS 阈值下超过了 SOTA RGB 方案 MSFT(论文 [47])。即在"差不多对就行"的标准下,雷达版骨架估计反而比同期最强 RGB 模型更稳——作者归因于新的指数分类损失抑制了过拟合。但在严格 KS=0.75 阈值下 RGB 依然占优,所以不是"RF 全面赢",而是"RF 在容忍误差的场景下与 RGB 相当"。
- 不同障碍物的衰减程度差异(Figure 10):木板、纸板几乎不影响;砖、石膏板有轻微影响;塑料居中。这个排序与各材料的介电常数(dielectric constant) 成正比——介电常数越高,反射越多透射越少。这是个漂亮的物理验证。
所以这一节是想说:穿墙不是噱头,从数据看核心关节追得跟 RGB 一样准;末梢肢体和单帧推理依然是软肋;不同墙的影响排序也符合物理预期。
你应该懂的几个新词
- RF(Radio Frequency,射频):电磁波里频率从几十 kHz 到 300 GHz 的那一段。论文用的是 3.3-10 GHz(Wi-Fi 频段)。类比:可见光是窄窄一段彩虹,RF 是更宽的"看不见的彩虹"。日常你接触到的微波炉、Wi-Fi、4G/5G 都属于 RF。
- FMCW(Frequency-Modulated Continuous Wave,调频连续波):发射端不发一个固定频率,而是让频率随时间线性升高。类比:唱"嘀——"从低音滑到高音,根据回声音高比你嘴里慢多少,倒推距离。汽车自动驾驶用的毫米波雷达也是 FMCW,原理一模一样。
- Antenna Array(天线阵列):好几根天线排成阵,不只是叠加信号强度,更能算出信号是从哪个角度来的。类比:人有两只耳朵就能定位声音方向(双耳时间差),天线阵列同理,只是用电波的相位差。论文给了角分辨率公式 Δθ = 0.886λ/(nd),意思是天线越多、间距越大,分辨率越高。
- Specularity(镜面反射):当物体表面相对波长来说是"光滑"的,电波就只朝特定方向反射,而不是四面八方散开。类比:用手电筒照一面镜子,只有正对的时候才看到光斑;照一张白纸(漫反射)则四面都能看见。RF 在 5cm 波长下,几乎所有物体表面对它都是"镜子"。
- Heatmap(热图):用颜色深浅或亮度表示一个二维网格里每格的"强度"。类比:天气预报里降水量地图,红色地方代表雨大。本文的雷达热图是"哪里反射回的能量强"。
- CNN(Convolutional Neural Network,卷积神经网络):神经网络的一种,专门擅长处理图像,因为它只关心局部小区域且所有位置共享同一组权重。类比:你认朋友的脸,是看眼睛+嘴巴附近的局部特征,不是把整张脸压成一长串数字。本文的 CNN 骨干是 DarkNet-53。
- RPN(Region Proposal Network,区域候选网络):从一张特征图里"画框"圈出可能有物体的位置。类比:监控员先在视频里圈出"这一块好像在动",再细看里面是人是猫。RPN 是 Faster R-CNN 的核心创新,本文借来检测多人。
- LSTM(Long Short-Term Memory,长短期记忆):RNN 的改良版,靠输入门、遗忘门、输出门有选择地保留信息,能记住几十步前发生的事。类比:你在听一段长故事时能想起开头讲了什么;普通 RNN 像只能记住最近一句话的金鱼。
- OKS(Object Keypoint Similarity):评估关节点估计准确度的指标,本质是"预测点离真实点多远"打分,用一个高斯函数把距离转成 0-1 分数。类比:你画地图标景点,离真实位置越近分越高。OKS=0.75 是严格匹配,OKS=0.5 是宽松匹配。
- Cross-Modal Supervision(跨模态监督):用一种数据生成的标签,去监督另一种数据上训练的模型。类比:哥哥学英语,妹妹用中文跟他对照——哥哥永远不直接学语法书。是这条研究线(RF 感知、激光雷达感知)共有的训练范式。
- Siamese Network(孪生网络):两个权重共享的子网络,把两个输入分别编码成向量,再比较距离。类比:让两个一模一样的考官分别给两份卷子打分,然后比较分数差。本文用它判断"前一帧的人和这一帧的人是不是同一个"。
- BODY-15:本文采用的关键点定义——头、肩×2、肘×2、手×2、髋×2、膝×2、脚×2 共 15 个点。类比:把人简化成纸片小人画法。OpenPose 默认用 25 点,本文砍到 15 是因为 RF 分辨率撑不起更细。
所以这一节是想说:理解这篇论文,关键是把"雷达术语(RF/FMCW/天线阵列/镜面反射)""神经网络术语(CNN/RPN/LSTM/Siamese)""跨模态学习术语(OKS/跨模态监督/BODY-15)"这三套词都摸过一遍。
它有什么搞不定的
- 末梢肢体(手、脚)经常丢:表面积小、镜面反射方向窄,几秒内可能根本反射不回任何信号。Table 3 里手在严格匹配(KS=0.75)下只有 30% 准确率,脚 40%。这不是模型的错,是物理的极限。
- 静止不动的人会"消失":many-to-many 范式的根基是"人在动,不同时刻不同肢体反射回来"。要是一个人僵在床上不动,LSTM 拼不出完整骨架——讽刺的是搜救场景里昏迷者经常就是不动的。要解决这点,可能要靠多个雷达从不同角度同时打(论文 Future Work 里提到的"立体 RF 成像")。
- 金属和厚混凝土仍然挡得住:木板、石膏板效果很好,但论文未声称能穿厚承重墙或带钢筋的混凝土。dielectric constant 高的材料反射多、透射少,物理上很难绕开。商用建筑里常见的金属龙骨、钢筋网都是 RF 杀手。
- 依赖 OpenPose 老师的覆盖:训练阶段必须有 RGB 摄像头能"看见"人,老师才能给出标签。也就是说模型从未在"全黑环境"或"老师都看不见"的场景里训练过——它对完全未见过的极端 RF 模式可能完全不知所措。
- 隐私和伦理空白:论文压根没讨论这玩意儿一旦量产,邻居互相照、雇主照员工怎么管。这是技术早于规范的典型案例。
所以这一节是想说:穿墙不是无敌——薄墙能穿,厚金属穿不动;动态人能拼,静态人拼不出;老师没看见的场景学生学不会。物理边界、训练分布、伦理边界都是论文留给后人的作业。
一个完整的训练流程示意
为了让你抓住整体节奏,把 5 步串起来看:
- 录数据(步骤 1):摄像头+雷达同步录 75,000 对样本,覆盖 11 种墙、4 种环境。
- 生成标签(步骤 1+3):OpenPose 在 RGB 图上画 15 个关节点,作为这一帧的"标准答案"。
- 预处理 RF(步骤 2):3D 点云转笛卡儿,再压成水平 + 垂直两张 2D 热图。
- 学生训练(步骤 3+4):连续若干帧 RF 热图喂入 CNN → RPN → LSTM → 全连接,输出每人 15 关节坐标。
- 算损失反传(步骤 4):联合损失 L = L_RPN + 0.75·L_track + L_cls,Adam 优化。
- 部署推理(步骤 5):摄像头不要了,只用雷达,0.056 秒一帧实时输出骨架。
整个流程的精妙之处是训练阶段的"作弊设备"在推理阶段全部退场——只有学生上岗,老师退休。这是跨模态学习的标准模式,但本文是把它做到 RF 这个新模态上的成功案例。
所以这一节是想说:从录数据到部署,这套流水线是一个"训练用双模态、推理用单模态"的经典闭环。
它和别的论文是什么关系
- MIT 的 RF-Pose(CVPR 2018,Zhao et al. [35]):直接的"前辈+对手"。两篇都用 RGB 摄像头当老师监督 RF 学生,但前辈用 3D CNN 处理时间维度,本文换成 CNN+LSTM,作者引用 Zuo et al. [36] 论证后者更优。如果你想看这条研究线的源头,应该先读 [35]——它定义了"用 RF 看人"这个问题。
- OpenPose(Cao et al., CVPR 2017,论文 [20]):本文的"老师模型"。所有 RF 模型的标签都来自 OpenPose 的输出,所以OpenPose 错了,学生也跟着错——这是跨模态监督的内禀风险。本文用的是 BODY-15 关键点定义而不是 OpenPose 默认的更细粒度版本,因为 RF 分辨率根本撑不起更多关节。
- YOLOv3(Redmon, 2018):本文的多人检测骨干。DarkNet-53 当 CNN 特征提取器,YOLOv3 的 anchor-based 多框预测当 RPN。这是个典型的"借用 RGB 视觉成熟模块改造到新模态"的工程做法。
- Faster R-CNN(Ren et al., NIPS 2015,论文 [25]):RPN 这个概念的发源地。本文 ROI Pooling 也是从这里来的。
- Siamese Networks(Tao et al., CVPR 2016,论文 [44]):本文跟踪损失的灵感来源。原版 Siamese 用于"目标跟踪"——给一张目标图、一张候选图,判断是不是同一个。这里改造成"同一个人在不同时刻的特征要相似",把跟踪问题转化成度量学习。
- 跟我们 notes/ 里其他论文的对照:
- 跟 LLaVA 类比:如果 LLaVA 是"教 LLM 长出眼睛",那 RF-Pose 就是"教模型长出 X 光眼"——两篇都在做"扩展感知边界",但模态完全不同。LLaVA 解决的是 AI 理解 视觉(已有视觉,让它会说话),本文解决的是 AI 生成 一种新的视觉(从无到有,让电波"显形")。
- 跟基于扩散策略 / VLA 这类"动作生成"论文的对比:本文不输出动作,只输出感知(骨架)。但你可以把它当成具身智能流水线的前级感知模块——一个会被搜救机器人当作输入的"穿墙摄像头"。机器人接到骨架后才决定要怎么走、怎么救。
- 跟数据集类(dataset-eval)论文相比,本文有个反例式启示:数据采集设备的物理特性(specularity)会决定模型架构选择。这是一种"数据→架构"的耦合,不是单纯堆数据就能解决的。如果你不懂 RF 的镜面反射特性,可能会以为多采点数据就能让单帧准——其实物理上根本不可能。
- 跟 World Model 论文比:World Model 在内部模拟世界,预测未来;本文在外部"看穿"世界,把不可见变可见。两者结合就是科幻里的"墙后透视眼镜+预测引擎"。
所以这一节是想说:这篇是 RF 感知线 2018 → 2019 的接力棒,骨架来自 RF-Pose 思路,标签来自 OpenPose,多人检测来自 YOLOv3 + Faster R-CNN,跟踪来自 Siamese,应用想象力与具身智能感知模块对接。
一段话补充:为什么这篇值得现在的读者花时间
如果你只对 LLM 感兴趣,可能会觉得 2019 年的 RF 论文跟你没啥关系。但它在三件事上对今天的 embodied AI 研究者依然有教学价值:
- 跨模态师生范式是大模型时代的常用招式——今天用 LLM 给图像、视频、机器人轨迹打标签,本质和这里用 OpenPose 给 RF 打标签是同一套逻辑。理解了 RF-Pose 这种工程化版本,你就更容易抓住"哪些环节可以委派给已有模型"的设计直觉。
- 物理约束驱动架构设计——本文不是先有模型再去找问题,而是先看清"specularity 物理决定了单帧不够用",再选了 LSTM。这种"物理-架构对齐"思路在 robotics、imitation learning 里依然适用。
- 数据采集的"作弊设备"思想——只挡 RF 不挡摄像头的支架是个范例。今天做模仿学习时常用的"训练时有特权信息(如完美关节角度),推理时只有摄像头"也是同一思路。
所以这一节是想说:把 RF-Pose 当成一个"如何用现代 AI 驯服一个新感知模态"的样板工程,比当一个 RF 专门论文读,得到的迁移收益更大。
我建议这样读这篇
- 先看摘要 + Figure 1:掌握"输入是什么、输出是什么"——别被术语吓住。摘要把师生范式、CNN+RPN+LSTM、many-to-many 这三个关键词都点出来了,先记住这三个词。
- 跳到第 VII 章 Physics-Driven Design Considerations:这是全文最关键的"为什么要这么设计"——读懂镜面反射,后面 LSTM 的存在意义就自然了。这一章读懂了,全文 70% 的设计决策你都能猜到。
- 回头读第 V-VI 章:理解 FMCW、天线阵列、热图怎么生成。这部分公式看不懂没关系,记住"3D 雷达数据被压成两张 2D 图"就够。如果你想做硬件延伸,这章的公式(特别是 FMCW 的 Δt = Δf / k)必须理解。
- 细读第 VIII 章 G-J 节:LSTM、Siamese 跟踪、新的指数分类损失。这是模型设计的核心创新。LSTM 那块如果对 RNN 不熟,可以先去补 Hochreiter 1997 原文。
- 看 Table 3 + Figure 8/9/10:用数据感受"哪个关节准、墙挡了多大区别、many-to-many 真的有效"。Figure 9 是 ablation 中最重要的一张——证明 LSTM 不是装饰。
- 最后看 §XII Future Research:作者自己点出的下一步(多阵列立体成像)——是个适合做"延伸研究"的入口。如果你想跟进研究,从这开始找选题。
所以这一节是想说:先抓"问题—物理—架构"主线,再啃公式,最后看实验。这样不会被符号淹没。
还有一个跟我们项目语境(embodied AI)相关的对照:本文的"前向感知 + 后续处理"流水线,其实和具身智能 agent 的感知-规划-执行流水线非常像。如果未来有人想做"穿墙搜救机器人",本文这套就是它的"眼睛模块",输出的骨架可以被 VLA / 运动规划模型当作输入。这种"模态扩展型论文"(让 AI 能处理新输入)会一直作为基础设施被引用,不会因为后续大模型出现而过时——LLaVA 是这样,RF-Pose 也是。
所以这一节是想说:本文不是 LLM 时代的论文,但它定义的"如何把不可见物理量翻译成模型可消化的格式"在每一代 AI 系统里都需要有人做。
一些好奇心问答
Q1:穿墙看人,安全吗?合法吗? 作者强调发射功率 100 皮瓦 = Wi-Fi 的千分之一,对人体无害——比你天天用的路由器辐射还低三个数量级。合法性是另一个问题——美国 FCC 给 Walabot 做了民用合规认证,但隐私边界论文没讨论。设想一个场景:你在家洗澡,邻居装一个这玩意儿照墙过来,他能"看到"你的骨架。法律上算偷窥吗?现行隐私法规是基于"可见光视觉"写的,对 RF 透视没有明确规定。这是一项典型的"先做出来再讨论伦理"的研究。
Q2:为什么不直接用毫米波?毫米波雷达精度更高啊。 毫米波(>30 GHz)波长太短(几毫米),穿墙能力极弱——一面普通石膏板就能挡死。论文要的是穿透性,所以用 Wi-Fi 频段(更长波长 = 更强穿透 = 更低分辨率)。这是个典型的物理 trade-off。如果你只想看清楚不需要穿墙,毫米波是更优选择(自动驾驶现在用的就是毫米波)。本文的核心目标是搜救——必须穿墙——所以走另一条路。
Q3:LSTM 看多长时间?看太久不会延迟太大吗? 论文没明确给窗口长度,但暗示是几秒级别(够拼出多个肢体的反射)。延迟是真问题:理论上每帧推理 0.056 秒很快,但要等 LSTM 累积足够上下文才能给出第一帧准确预测——开机后有几秒"暖机期"。在搜救场景这几秒可以容忍,但实时反应要求高的场景(比如手术辅助)就够呛。
Q4:要是屋里有 5 个人,会不会乱掉? RPN 设计上支持多人,每个人有独立的"指纹特征",靠 Siamese 风格的 tracking loss 让模型把同一个人在不同时刻的预测绑定起来。但论文没专门做大规模多人测试(最多展示了几人场景),作者承认这是未来工作。多人场景下,RF 的问题不只是检测,还有遮挡——一个人挡在另一个人前面,后面那位的反射会被前面挡住。这是物理上无法避免的。
Q5:摄像头老师有时也会出错,那学生模型不就被带歪了? 对,这是跨模态监督的根本风险。论文没有专门处理这件事,只是在损失函数里乘了一个 OpenPose 的置信度——老师没把握的样本权重小一些。但如果 OpenPose 系统性偏差(比如对深肤色人识别更差),学生会继承这个偏差。研究伦理上这是个隐患:训练数据来源决定了部署后的公平性。
Q6:和 MIT 的 RF-Pose 比,进步在哪? 三点:1) CNN+LSTM 替代 3D CNN(理论上时序聚合更好);2) 显式加了"穿障碍物"的训练数据;3) 加了 Siamese 多人跟踪损失和指数分类损失。但客观说,这是工程改进而非范式革命——核心思想(RGB 监督 RF)是 RF-Pose 已经定下的。要做范式级别的突破,可能要等到把 LSTM 换成 Transformer,或者完全不依赖 RGB 老师(自监督)的工作。
Q7:作者 Kevin Meng 是谁?为什么挂着 ACM Student Member? 作者当时是 Plano(德州)一个高中生(搭配 IEEE Senior Member 的父亲合作),这篇是 high school + 自学项目水准的论文,登在 arXiv 而非顶会。这并不意味着工作不好——反而说明 RF 姿态估计的思路在 2019 已经"民主化"到高中生能复现。但严谨度上确实没经过顶会同行评审,所以读的时候要带着一点"批判性阅读"的眼光:作者的损失加权 4:3:4、超参数选择往往没有详尽的消融。
Q8:能跑在树莓派上吗? 论文跑在普通 GPU 上(作者没说具体型号)。0.056s/帧的实时性指的是 GPU。要塞进树莓派,至少需要模型蒸馏和量化——是适合做硕士毕设的工程化方向。也可以考虑把骨干网络从 DarkNet-53 换成 MobileNet 之类的轻量级架构,是个明确的优化路径。
Q9:为什么不用 Transformer?2019 年 Transformer 不是已经火了吗? NLP 领域是火了(BERT 2018),但视觉 Transformer(ViT)要到 2020 才出现。2019 年视觉时序任务的工业默认还是 CNN+LSTM。如果今天重做,用 Vision Transformer + Temporal Transformer 替代 CNN+LSTM 是显然的方向,可能在多人混淆场景下表现更好(注意力机制对"哪些信号属于哪个人"建模更直接)。
Q10:训练用 OpenPose 当老师,那推理时还需要摄像头吗? 不需要——这是这套设计最优雅的地方。摄像头只在训练阶段当老师,部署阶段只有雷达。所以你可以把训练好的模型放进一个完全没有摄像头的搜救机器人里。但代价是:模型被 OpenPose 见过的姿态分布锁住了——OpenPose 没在训练数据里见过的姿势(比如倒立、瑜伽极限动作),雷达模型也学不会。
Q11:如果换一个房间、换一面墙,模型还工作吗? 论文的训练数据覆盖了 11 种障碍物 + 4 种环境,所以对常见住宅/办公环境的泛化是 OK 的。但如果换到完全没见过的材料(比如水帘、玻璃幕墙)或者非典型几何(拱形天花板),可能会有性能下降。这是 specularity-driven 模型的固有问题:物理规律虽然普适,但具体反射模式跟环境强相关。
Q12:和现在(2026 年)流行的"WiFi sensing"关系是什么? 这是同一个研究家族的祖辈。最近几年 WiFi sensing 朝两个方向发展:1)用商用路由器的 CSI(Channel State Information)做感知,硬件成本更低;2)用大模型(如基于 Transformer 的多模态架构)替代 CNN+LSTM。本文虽然 2019 年的工作,但**"师生跨模态训练"和"many-to-many 时序推理"这两个核心思想被新工作不断继承**。
所以这一节是想说:这篇论文的物理基础很扎实,工程贡献清楚,但伦理、规模、部署还有很多没回答的空白。它的核心思想(跨模态师生训练、时序聚合解决物理稀疏性)至今仍在新一代 RF 感知工作里反复出现。
如果你想再深入
- Zhao et al., CVPR 2018, "Through-Wall Human Pose Estimation Using Radio Signals"(论文 [35]) — MIT 的 RF-Pose,是这条研究线的真正起点。理解了它,本文的"改进"就清楚了。MIT 后续还有 RF-Pose3D(输出 3D 骨架而非 2D)、RF-Avatar(输出 SMPL 网格而非骨架点)等延伸工作,整条线索可以串起来读。建议阅读顺序:RF-Pose(2018)→ 本文(2019)→ RF-Pose3D(2018-2019)→ RF-Avatar(2020)。
- Cao et al., CVPR 2017, OpenPose(论文 [20]) — 教你 RGB 多人姿态估计是怎么做的。Part Affinity Fields(PAF,部位关联场)是亮点,理解 PAF 之后,你会明白本文的老师模型为什么这么强、为什么 BODY-15 是合理的简化。读 OpenPose 也能让你看清"自顶向下 vs 自底向上"两种多人姿态估计范式的差别。
- Ren et al., NIPS 2015, Faster R-CNN(论文 [25]) — RPN 的发源地。本文的多人检测全靠这个机制。同时也是理解后续 YOLOv3 改进点的必备背景。如果你只读这一篇 RPN 论文,记住"用 anchor 框 + 二分类 + 回归"这个三件套就行。
- Hochreiter & Schmidhuber, 1997, "Long Short-Term Memory"(论文 [27]) — LSTM 原始论文。如果想懂为什么能记长依赖,源头在这。可以配 [29] Werbos 的 BPTT 一起看。这是 1990s 末的工作,至今工业上仍在大量使用——足见其稳健性。
- Walabot SDK 文档(https://api.walabot.com/) — 这是论文用的硬件官方手册。如果你想自己复现,先读这个比读论文公式管用——价格几百美元的设备就能跑起来一套类似系统。Walabot 已经被很多教学项目当作"入门级 RF 感知硬件"。
- Adib et al., 2014-2015 系列工作(论文 [7][41]) — MIT CSAIL 的 RF 感知早期论文,"Capturing the Human Figure Through a Wall",是把 RF 用于人体感知的开拓性工作。Fadel Adib 现在在 MIT Media Lab 主持 Signal Kinetics Group,整个组的工作就是 RF 在不同任务上的扩展。
- 演示视频(https://youtu.be/7hX8qGJdWno) — 论文作者放的 demo,能直观看到模型实时跑起来什么效果。读论文之前先看 30 秒的 demo,对你建立直觉很有用。
所以这一节是想说:要复现,先搞硬件 SDK;要理解理论,先读 RF-Pose 前辈和 OpenPose 老师;要扩展,看 RPN 和 LSTM 的源头;要追溯整条研究线,从 Adib 2014 一路读到 RF-Avatar;要建立直觉,先看 demo 视频。
笔记作者的读后感
读完这篇最大的感受是:它不是一篇"用大模型打天下"的论文,反而是一篇"很会动手"的论文。从挑硬件(Walabot)、设计协同支架、想出"摄像头作弊不挡 RGB"的训练设备、到把损失拆成三段配重,每一步都是工程化思考的产物。这种"先把物理摸清楚再下网络"的研究方式,在今天 LLM 万物归一的氛围里反而更难得。
如果未来想做"具身 AI + 新感知模态"(比如声呐、激光雷达、化学传感器),这篇论文给的方法论模板比它的具体技术细节更值得借鉴。读懂物理 → 设计监督 → 选对架构 → 做对数据,每一步缺一不可。
所以这一节是想说:这是一篇适合"动手派研究者"的论文,物理直觉与工程巧思胜过模型规模本身。
笔记结束。如果你只记住一件事:在物理约束很强的传感任务里,"用一个成熟模态当老师监督新模态"+"靠时序累积补偿单帧稀疏"是一条经过验证的可复制路径。
◼
引用本笔记 / Cite this note
@online{eai_rf_pose_through_wall_2026,
title = {(readable note) Through-Wall Pose Imaging in Real-Time with a Many-to-Many Encoder/Decoder Paradigm},
author = {Zhou, Jason},
year = {2026},
note = {Note on a 2019 paper},
howpublished = {\url{https://estelledc.github.io/embodied-ai-reading-station/papers/rf-pose-through-wall/}},
organization = {Embodied AI Reading Station}
}
All 156 papers (full index)
- 1. LLaVA: Visual Instruction Tuning
- 2. 3DShape2VecSet: 3D Shape Representation for Diffusion Models
- 3. SayCan: Do As I Can, Not As I Say
- 4. OpenVLA: An Open-Source Vision-Language-Action Model
- 5. VLAS: VLA Model With Speech Instructions
- 6. MLA: Multisensory Language-Action Model
- 7. Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control
- 8. CartoRadar: RF-Based 3D SLAM Rivaling Vision Approaches
- 9. mmCLIP: Boosting mmWave-based Zero-shot HAR via Signal-Text Alignment
- 10. mmNorm: Non-Line-of-Sight 3D Object Reconstruction via mmWave Surface Normal Estimation
- 11. Proactive Hearing Assistants that Isolate Egocentric Conversations
- 12. NeuralAids: Wireless Hearables With Programmable Speech AI Accelerators
- 13. Creating speech zones with self-distributing acoustic swarms
- 14. Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation
- 15. SoundStream: An End-to-End Neural Audio Codec
- 16. AudioLM
- 17. Conformer
- 18. Dual-path RNN
- 19. EnCodec
- 20. Meta-StyleSpeech
- 21. MusicLM
- 22. Robust Speech Recognition via Large-Scale Weak Supervision
- 23. SeamlessM4T
- 24. Stable Audio
- 25. Universal Source Separation with Weakly Labelled Data
- 26. Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning
- 27. RLBench: The Robot Learning Benchmark & Learning Environment
- 28. robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
- 29. BridgeData V2
- 30. CALVIN
- 31. LIBERO
- 32. RH20T
- 33. What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
- 34. DROID
- 35. Open X-Embodiment
- 36. RoboCasa
- 37. SimplerEnv
- 38. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
- 39. 3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
- 40. Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation
- 41. EquiBot: SIM(3)-Equivariant Diffusion Policy
- 42. DiT-Policy
- 43. Diffusion Policy Policy Optimization (DPPO)
- 44. Affordance-based Robot Manipulation with Flow Matching
- 45. FlowPolicy: 3D Flow-based Policy via Consistency Flow Matching
- 46. FAST: Efficient Action Tokenization for VLA
- 47. pi_0: Vision-Language-Action Flow Model
- 48. pi_0.5: VLA with Open-World Generalization
- 49. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
- 50. Generative Adversarial Imitation Learning
- 51. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (ACT/ALOHA)
- 52. AnyTeleop
- 53. Behavior Transformers: Cloning k Modes with One Stone
- 54. Implicit Behavioral Cloning
- 55. RoboCat
- 56. ALOHA 2
- 57. DexCap
- 58. HumanPlus
- 59. Generalizable Humanoid Manipulation with 3D Diffusion Policies (iDP3)
- 60. Mobile ALOHA
- 61. SmolVLA
- 62. Universal Manipulation Interface
- 63. Behavior Generation with Latent Actions (VQ-BeT)
- 64. ImageBind: One Embedding Space To Bind Them All
- 65. Connecting Touch and Vision via Cross-Modal Prediction
- 66. AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
- 67. AudioPaLM
- 68. FROMAGe: Grounding LLMs to Images
- 69. OneLLM
- 70. X-VLM: Multi-Grained Vision Language Pre-Training
- 71. Tactile Beyond Pixels (Sparsh-X)
- 72. Sparsh: Self-supervised Touch Representations
- 73. Tactile-VLA
- 74. TLA: Tactile-Language-Action
- 75. Code as Policies: Language Model Programs for Embodied Control
- 76. Inner Monologue: Embodied Reasoning through Planning with Language Models
- 77. LLM+P: Empowering LLMs with Optimal Planning
- 78. PaLM-E: An Embodied Multimodal Language Model
- 79. ProgPrompt
- 80. ChatGPT for Robotics
- 81. GenSim
- 82. RoboFlamingo
- 83. Tree-Planner
- 84. VoxPoser
- 85. See Through Smoke: Robust Indoor Mapping with Low-cost mmWave Radar
- 86. Can WiFi Estimate Person Pose?
- 87. 3DRIMR: 3D Reconstruction and Imaging via mmWave Radar based on Deep Learning
- 88. milliEgo: Single-chip mmWave Radar Aided Egomotion Estimation via Deep Sensor Fusion
- 89. High Resolution Point Clouds from mmWave Radar
- 90. RadarSLAM: Radar based Large-Scale SLAM in All Weathers
- 91. Through-Wall Pose Imaging in Real-Time with a Many-to-Many Encoder/Decoder Paradigm
- 92. RFMask: A Simple Baseline for Human Silhouette Segmentation with Radio Signals
- 93. RFPose-OT: RF-Based 3D Human Pose Estimation via Optimal Transport Theory
- 94. Argus: Multi-View Egocentric Human Mesh Reconstruction Based on Stripped-Down Wearable mmWave Add-on
- 95. Diffusion Model is a Good Pose Estimator from 3D RF-Vision
- 96. Enabling Visual Recognition at Radio Frequency (PanoRadar)
- 97. Wave-Former: Through-Occlusion 3D Reconstruction via Wireless Shape Completion
- 98. Habitat: A Platform for Embodied AI Research
- 99. Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
- 100. DexMV
- 101. Habitat 2.0
- 102. ManiSkill
- 103. ProcTHOR
- 104. SAPIEN: A SimulAted Part-based Interactive ENvironment
- 105. BEHAVIOR-1K
- 106. Habitat 3.0
- 107. Isaac Lab
- 108. MuJoCo Playground
- 109. RT-1: Robotics Transformer for Real-World Control at Scale
- 110. 3D Diffusion Policy (DP3)
- 111. Octo: An Open-Source Generalist Robot Policy
- 112. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- 113. RT-Trajectory: Robotic Task Generalization via Hindsight Trajectory Sketches
- 114. 3D-VLA
- 115. DexVLA
- 116. GR-2: Generative Video-Language-Action Model
- 117. OpenHelix
- 118. OpenVLA-OFT
- 119. RDT-1B: Diffusion Foundation Model for Bimanual Manipulation
- 120. RoboMamba
- 121. SpatialVLA
- 122. TinyVLA
- 123. TraceVLA: Visual Trace Prompting
- 124. Learning Transferable Visual Models From Natural Language Supervision
- 125. Flamingo: a Visual Language Model for Few-Shot Learning
- 126. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 127. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- 128. DeepSeek-VL: Towards Real-World Vision-Language Understanding
- 129. EVA-CLIP: Improved Training Techniques for CLIP at Scale
- 130. FILIP: Fine-grained Interactive Language-Image Pre-Training
- 131. Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
- 132. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
- 133. Improved Baselines with Visual Instruction Tuning
- 134. OBELICS
- 135. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
- 136. Sigmoid Loss for Language Image Pre-Training
- 137. What matters when building vision-language models?
- 138. Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
- 139. The Llama 3 Herd of Models
- 140. LLaVA-NeXT-Interleave
- 141. LLaVA-OneVision: Easy Visual Task Transfer
- 142. Long-CLIP: Unlocking the Long-Text Capability of CLIP
- 143. Pixtral 12B
- 144. Dream to Control: Learning Behaviors by Latent Imagination
- 145. World Models
- 146. DayDreamer
- 147. Mastering Atari with Discrete World Models
- 148. Dreamer V3: Mastering Diverse Domains through World Models
- 149. Transformers are Sample-Efficient World Models
- 150. TWM: Transformer-based World Models
- 151. 1X World Model Challenge
- 152. Cosmos World Foundation Model Platform
- 153. GAIA-1
- 154. Genie: Generative Interactive Environments
- 155. Navigation World Models
- 156. UniSim