FILIP: Fine-grained Interactive Language-Image Pre-Training
本笔记基于摘要 + 公开资料,未读全文。
一句话讲什么(TL;DR)
以前是"整张图配整句话",FILIP 让图的每一小块和句子的每个词互相找最像的伙伴,模型就能学会"狗在左下角"这种细节。
这是个什么场景
想一下你在淘宝搜"红项圈柯基",希望平台能精准给出"戴红项圈的柯基",而不是"任何柯基"或"任何红项圈"。
这背后要解决的事情,本质上就是:模型要不要在意句子里的细节词,对应图里的具体哪一块?
- 以前的玩法(CLIP):像让你做选择题。给一整张图配一整段描述,你只回答"配 / 不配"。你能学会"狗的图配狗的句子",但你不会被逼着去想"句子里的'红项圈'到底对应图里的哪个角落"。
- FILIP 的玩法:像玩拼图找词。图被切成几十块小拼图,句子被拆成几个词。每块小拼图都要在词列表里挑一个"最像它的词";反过来每个词也要在拼图里挑一块"最像它的小块"。最后把这些"最佳配对得分"加起来,才是图文整体的匹配分。
这种玩法会逼模型去想清楚"红项圈"这个词对应图里哪一小块。结果是模型不只整体懂图,还懂图的细节——零样本分类时它能更准地分辨细类,迁移到下游任务时也更稳。

之前的人怎么做的 — 3-5 bullet
- CLIP(2021):双塔 + 全局对比学习。图像编码器输出
[CLS]一个向量,文本编码器输出[EOS]一个向量,两者点积。简单、可扩到 4 亿对图文。缺点:粒度太粗,看不清"句子里某个名词到底指图里哪一块"。 - ALIGN(2021):和 CLIP 同思路,更暴力的数据规模(18 亿对噪声网页图文),证明数据量够大可以补质量。仍然是全局对齐。
- 早期视觉-语言预训练(ViLBERT / UNITER / OSCAR):单塔或交叉编码器,用 BERT-like 注意力让 region 和 token 强交互。优点:细粒度好;缺点:推理时图文必须一起 forward,零样本图像分类成本高,做不了像 CLIP 那样的"先编码图库,再快速比对"。
- DeCLIP / SLIP(2021):在 CLIP 基础上加自监督、masked LM、最近邻挖掘等辅助任务,提升数据效率。但仍是全局对齐。
- 总结:双塔(CLIP 系)= 部署快但粒度粗;单塔(UNITER 系)= 粒度好但不能零样本批量分类。FILIP 想要"双塔的部署优势 + 单塔的细粒度"。
这篇论文的关键想法
核心:把"两个全局向量做点积"换成"两组 token 向量做最大相似度匹配再平均"。
公式上(直觉版):
- CLIP:
sim(image, text) = <v_global, t_global> - FILIP:
sim(image, text) = mean_i max_j <v_i, t_j> + mean_j max_i <v_j, t_i>(双向 token-level max)
这个改动看似小,但有两个深意:
- 不增加推理成本:图像和文本仍然各自独立编码(双塔结构没变),只是相似度计算从一个点积变成 token 矩阵的"最大值池化 + 平均"。零样本分类时,文本 token 可以预先缓存。
- 强迫局部对齐:训练目标是让"每个 patch 找到的最佳 token"得分高。模型要让 patch 的语义指向某个词,否则 max 操作给不了高分。这就把局部对应关系作为"副产品"学出来了。
附带好处:可解释性——训练完后可以可视化每个 token 对应图里哪些 patch,得到一个免费的 grounding map(词 → 图像区域映射)。
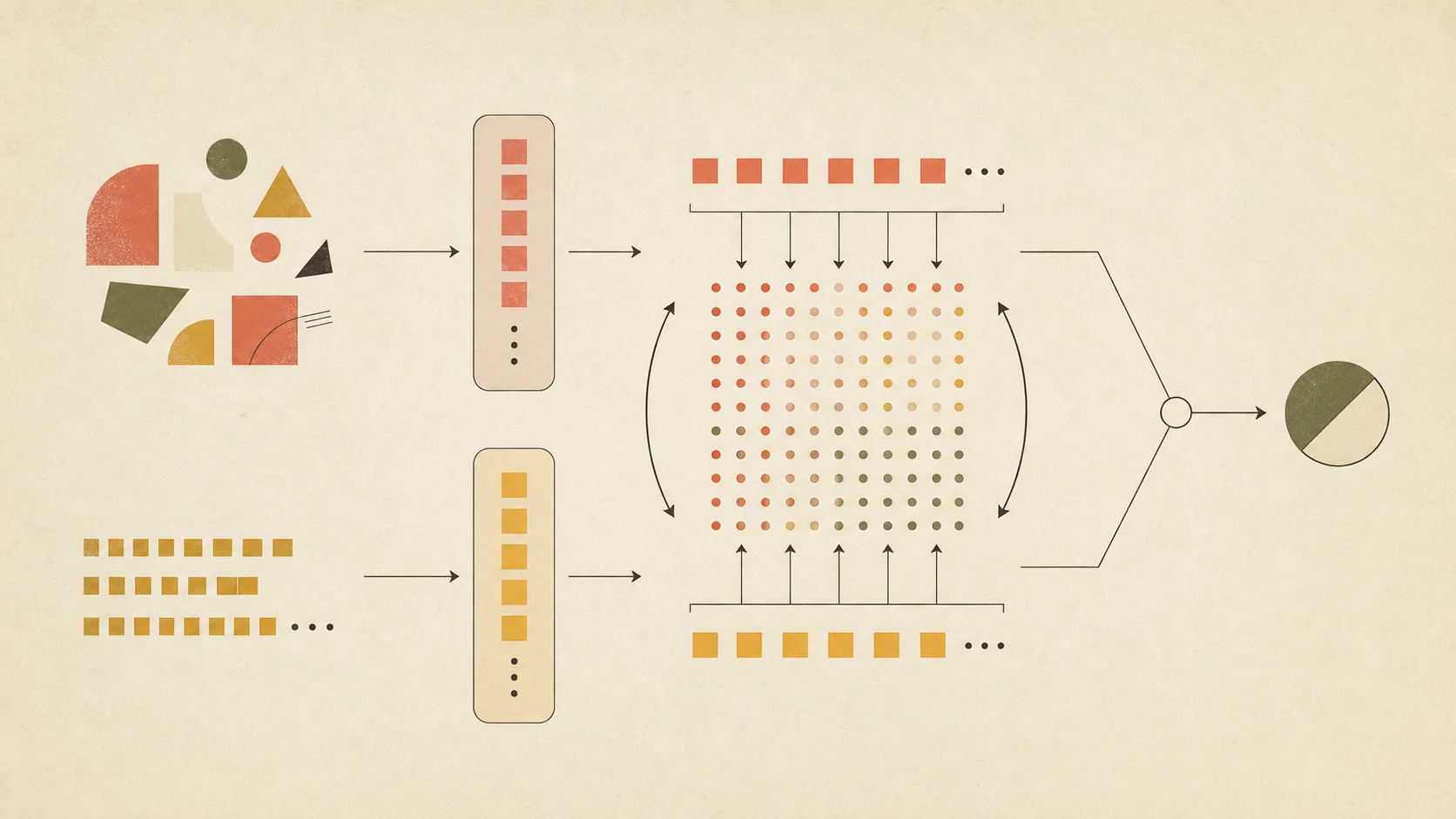
它怎么做的(方法)— 3-4 段
整体架构(像两条独立的流水线):左边一条线管图(ViT,视觉 Transformer),右边一条线管文字(BERT-like 文本 Transformer)。两条线各自处理,互不串门,到最后一层才碰面。这点和 CLIP 完全一样。区别只在它们碰面之后怎么算相似度。
Token-level 相似度计算(像班长配对游戏):图像编码器吐出 N 个 patch token(小拼图块的向量),文本编码器吐出 M 个 word token(词的向量)。对每块拼图,让它在所有词里挑一个"最像我的",记下这个最高分;N 块都挑完后取平均,得到"图到文"的分数。反过来再让每个词在所有拼图里挑一个最像的,得到"文到图"的分数。两个方向取平均,就是最终相似度,喂给对比学习的 InfoNCE 损失。
等等,先慢一拍 — patch token 和 InfoNCE 是什么?
- patch token:ViT 把图像切成 16×16 或 32×32 的方块,每个方块编码成一个向量。可以想成"图像的词"。
- InfoNCE:对比学习的标准训练方式。把同一对图文当"正确答案",同一批里其他对当"错误答案",让模型把正确答案的相似度拉高、把错误答案压低。FILIP 没改这个损失,只换了相似度算法。
为什么用 max(硬选)而不是 sum 或 attention(软加权):max 像"班长只能挑一个搭档",逼每块拼图找到一个明确归属。如果允许它"每个词都沾一点"(attention 的软加权),那"红项圈"这种细节就会被稀释成"狗的整体氛围",反而学不到精确对应。具体消融数字需读原文。
数据与规模:FILIP 在自建的 3 亿对图文数据上预训练(具体数字需读原文,量级在 CLIP 4 亿和 ALIGN 18 亿之间)。还配了图像增广和 prompt ensemble 来增强零样本评测。重点不是数据量碾压,而是证明"即使数据不到 CLIP 一半,细粒度交互也能追上甚至超越"。
实验在做什么
主要从四个维度评估,目标是证明"细粒度对齐确实带来更好的图文表征":
- 零样本图像分类(Zero-shot ImageNet 等 12 个数据集):和 CLIP / ALIGN 在同 backbone 下比 top-1。FILIP 在多个数据集上超越同规模 CLIP,尤其是细粒度数据集(鸟类、车型、食物等)。具体数字需读原文。
- 零样本图文检索(Flickr30K、MS-COCO):图到文 R@1 / 文到图 R@1 提升明显,因为细粒度对齐天然适合"句子里某个细节对应图里某块"的检索。
- 下游迁移(线性探测、Linear Probing):把预训练好的视觉编码器冻住,在 ImageNet、VTAB 等下游任务上线性探测,看表征质量。FILIP 和 CLIP / ALIGN 持平或更好。
- 可解释性可视化:展示训练完后,给定一个文本 token(比如 "dog"),可视化它在图像里 max 匹配到了哪些 patch——通常能定位到狗所在的区域。这是 CLIP 做不到的副产品。
消融实验关注:max vs mean vs attention 的对比;图文双向 max vs 单向;prompt ensemble 的贡献;数据规模的影响。具体数字需读原文。
你应该懂的几个新词 — 4-6 个
- Patch token / Word token:ViT 把图像切成 16x16 或 32x32 的小块(patch),每块编码成一个向量;BERT 把文本切成词或子词(word piece),每个也是一个向量。FILIP 在这两组 token 之间做匹配。
- Late interaction(晚交互):图文各自独立编码到底(不互相 attention),只在最后一层算 token 级相似度。这是相对于 early interaction(单塔交叉注意力)的概念。FILIP 属于晚交互的一种。同期 ColBERT 在文本检索领域也用类似思路。
- InfoNCE 损失:对比学习的标准损失。把"匹配的图文对"当正样本,同 batch 里其他对当负样本,最大化正对相似度、最小化负对。FILIP 把相似度算法换了,但损失函数没变。
- Token-wise max similarity:对每个 token,在另一模态里取最大相似度。这是 FILIP 的核心算子。"硬"选择,而非软加权。
- Dual encoder(双塔):图像编码器和文本编码器独立,最后只在向量空间做相似度。和单塔(cross-encoder)相对。FILIP 属于双塔,但相似度计算更精细。
- Grounding(落地 / 接地):把语言里的概念对应到图像里的具体区域。FILIP 的 token-wise max 天然产生 grounding 信号,无需显式监督。
它和其他论文什么关系
- 直接前驱:CLIP(2021)、ALIGN(2021)。FILIP 把这两者的全局对齐升级为细粒度。
- 思想近亲:ColBERT(信息检索领域,2020),同样用"token 级 late interaction"替代单向量检索。FILIP 可以看作 ColBERT 在视觉-语言场景的实现。
- 同期对比:DeCLIP / SLIP / DeFILIP 等都在尝试"如何用更少数据/更巧训练目标超越 CLIP"。FILIP 的路径是"换相似度算法",DeCLIP 的路径是"加辅助任务"。
- 后续影响:这种细粒度对齐思路被多个工作沿用。如果你在看 GLIP(2022, grounding 预训练)、X-VLM、FILIP 系扩展模型,理解 FILIP 的 token-level max 是基础。
- 下游联系:在具身 AI / VLA 模型里,需要"指令里的物体名词对应到摄像头画面里的某个区域",这正是 FILIP 学的东西。它是 grounding 类预训练的一个里程碑。
我建议这样读 — 3-4 步
- 先复习 CLIP:看清楚 CLIP 的相似度公式
<v_global, t_global>和 InfoNCE 怎么用。如果这步不清楚,FILIP 的"改进点"无法体会。 - 直接跳到 FILIP 方法图(Figure 2 或 3):看 token-wise max similarity 怎么算。手画一遍:N 个 patch 向量、M 个 token 向量,配 N×M 相似度矩阵,每行取 max 再平均。这一步搞懂,论文核心就掌握了 70%。
- 看消融表(max vs mean vs attention):理解为什么"硬 max"比软加权好。这是设计直觉的关键。
- 看可视化(grounding heatmap):感受一下 token 到 patch 的对应到底学到了什么。这是 CLIP 做不到的,也是 FILIP 价值的直观展示。
为什么值得读
- 算法思想优雅:一个简单的"max + mean"操作,把粗对齐变细对齐,没增加推理成本。这种"小改动大效果"是值得学习的设计风格。
- 可解释性副产品:免费得到 grounding map,对下游任务(检测、分割、机器人指令落地)非常有用。
- VLM 演进的关键节点:从 CLIP 到 GLIP / BLIP / Flamingo 这条线,FILIP 是"开始注意细粒度"的代表。理解它能帮你看懂后续一系列工作为什么走 token-level、region-level 路线。
- 对你(具身 AI 方向)的意义:机器人/VLA 模型经常需要"把指令里的'红色杯子'对应到摄像头画面的某个区域"。FILIP 这类预训练就是在给这个能力打基础。读懂它,下游 VLA 论文里"为什么用细粒度对齐"的问题就不再神秘。
◼
引用本笔记 / Cite this note
@online{eai_filip_2026,
title = {(readable note) FILIP: Fine-grained Interactive Language-Image Pre-Training},
author = {Zhou, Jason},
year = {2026},
note = {Note on a 2022 paper},
howpublished = {\url{https://estelledc.github.io/embodied-ai-reading-station/papers/filip/}},
organization = {Embodied AI Reading Station}
}
All 156 papers (full index)
- 1. LLaVA: Visual Instruction Tuning
- 2. 3DShape2VecSet: 3D Shape Representation for Diffusion Models
- 3. SayCan: Do As I Can, Not As I Say
- 4. OpenVLA: An Open-Source Vision-Language-Action Model
- 5. VLAS: VLA Model With Speech Instructions
- 6. MLA: Multisensory Language-Action Model
- 7. Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control
- 8. CartoRadar: RF-Based 3D SLAM Rivaling Vision Approaches
- 9. mmCLIP: Boosting mmWave-based Zero-shot HAR via Signal-Text Alignment
- 10. mmNorm: Non-Line-of-Sight 3D Object Reconstruction via mmWave Surface Normal Estimation
- 11. Proactive Hearing Assistants that Isolate Egocentric Conversations
- 12. NeuralAids: Wireless Hearables With Programmable Speech AI Accelerators
- 13. Creating speech zones with self-distributing acoustic swarms
- 14. Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation
- 15. SoundStream: An End-to-End Neural Audio Codec
- 16. AudioLM
- 17. Conformer
- 18. Dual-path RNN
- 19. EnCodec
- 20. Meta-StyleSpeech
- 21. MusicLM
- 22. Robust Speech Recognition via Large-Scale Weak Supervision
- 23. SeamlessM4T
- 24. Stable Audio
- 25. Universal Source Separation with Weakly Labelled Data
- 26. Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning
- 27. RLBench: The Robot Learning Benchmark & Learning Environment
- 28. robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
- 29. BridgeData V2
- 30. CALVIN
- 31. LIBERO
- 32. RH20T
- 33. What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
- 34. DROID
- 35. Open X-Embodiment
- 36. RoboCasa
- 37. SimplerEnv
- 38. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
- 39. 3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
- 40. Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation
- 41. EquiBot: SIM(3)-Equivariant Diffusion Policy
- 42. DiT-Policy
- 43. Diffusion Policy Policy Optimization (DPPO)
- 44. Affordance-based Robot Manipulation with Flow Matching
- 45. FlowPolicy: 3D Flow-based Policy via Consistency Flow Matching
- 46. FAST: Efficient Action Tokenization for VLA
- 47. pi_0: Vision-Language-Action Flow Model
- 48. pi_0.5: VLA with Open-World Generalization
- 49. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
- 50. Generative Adversarial Imitation Learning
- 51. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (ACT/ALOHA)
- 52. AnyTeleop
- 53. Behavior Transformers: Cloning k Modes with One Stone
- 54. Implicit Behavioral Cloning
- 55. RoboCat
- 56. ALOHA 2
- 57. DexCap
- 58. HumanPlus
- 59. Generalizable Humanoid Manipulation with 3D Diffusion Policies (iDP3)
- 60. Mobile ALOHA
- 61. SmolVLA
- 62. Universal Manipulation Interface
- 63. Behavior Generation with Latent Actions (VQ-BeT)
- 64. ImageBind: One Embedding Space To Bind Them All
- 65. Connecting Touch and Vision via Cross-Modal Prediction
- 66. AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
- 67. AudioPaLM
- 68. FROMAGe: Grounding LLMs to Images
- 69. OneLLM
- 70. X-VLM: Multi-Grained Vision Language Pre-Training
- 71. Tactile Beyond Pixels (Sparsh-X)
- 72. Sparsh: Self-supervised Touch Representations
- 73. Tactile-VLA
- 74. TLA: Tactile-Language-Action
- 75. Code as Policies: Language Model Programs for Embodied Control
- 76. Inner Monologue: Embodied Reasoning through Planning with Language Models
- 77. LLM+P: Empowering LLMs with Optimal Planning
- 78. PaLM-E: An Embodied Multimodal Language Model
- 79. ProgPrompt
- 80. ChatGPT for Robotics
- 81. GenSim
- 82. RoboFlamingo
- 83. Tree-Planner
- 84. VoxPoser
- 85. See Through Smoke: Robust Indoor Mapping with Low-cost mmWave Radar
- 86. Can WiFi Estimate Person Pose?
- 87. 3DRIMR: 3D Reconstruction and Imaging via mmWave Radar based on Deep Learning
- 88. milliEgo: Single-chip mmWave Radar Aided Egomotion Estimation via Deep Sensor Fusion
- 89. High Resolution Point Clouds from mmWave Radar
- 90. RadarSLAM: Radar based Large-Scale SLAM in All Weathers
- 91. Through-Wall Pose Imaging in Real-Time with a Many-to-Many Encoder/Decoder Paradigm
- 92. RFMask: A Simple Baseline for Human Silhouette Segmentation with Radio Signals
- 93. RFPose-OT: RF-Based 3D Human Pose Estimation via Optimal Transport Theory
- 94. Argus: Multi-View Egocentric Human Mesh Reconstruction Based on Stripped-Down Wearable mmWave Add-on
- 95. Diffusion Model is a Good Pose Estimator from 3D RF-Vision
- 96. Enabling Visual Recognition at Radio Frequency (PanoRadar)
- 97. Wave-Former: Through-Occlusion 3D Reconstruction via Wireless Shape Completion
- 98. Habitat: A Platform for Embodied AI Research
- 99. Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
- 100. DexMV
- 101. Habitat 2.0
- 102. ManiSkill
- 103. ProcTHOR
- 104. SAPIEN: A SimulAted Part-based Interactive ENvironment
- 105. BEHAVIOR-1K
- 106. Habitat 3.0
- 107. Isaac Lab
- 108. MuJoCo Playground
- 109. RT-1: Robotics Transformer for Real-World Control at Scale
- 110. 3D Diffusion Policy (DP3)
- 111. Octo: An Open-Source Generalist Robot Policy
- 112. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- 113. RT-Trajectory: Robotic Task Generalization via Hindsight Trajectory Sketches
- 114. 3D-VLA
- 115. DexVLA
- 116. GR-2: Generative Video-Language-Action Model
- 117. OpenHelix
- 118. OpenVLA-OFT
- 119. RDT-1B: Diffusion Foundation Model for Bimanual Manipulation
- 120. RoboMamba
- 121. SpatialVLA
- 122. TinyVLA
- 123. TraceVLA: Visual Trace Prompting
- 124. Learning Transferable Visual Models From Natural Language Supervision
- 125. Flamingo: a Visual Language Model for Few-Shot Learning
- 126. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 127. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- 128. DeepSeek-VL: Towards Real-World Vision-Language Understanding
- 129. EVA-CLIP: Improved Training Techniques for CLIP at Scale
- 130. FILIP: Fine-grained Interactive Language-Image Pre-Training
- 131. Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
- 132. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
- 133. Improved Baselines with Visual Instruction Tuning
- 134. OBELICS
- 135. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
- 136. Sigmoid Loss for Language Image Pre-Training
- 137. What matters when building vision-language models?
- 138. Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
- 139. The Llama 3 Herd of Models
- 140. LLaVA-NeXT-Interleave
- 141. LLaVA-OneVision: Easy Visual Task Transfer
- 142. Long-CLIP: Unlocking the Long-Text Capability of CLIP
- 143. Pixtral 12B
- 144. Dream to Control: Learning Behaviors by Latent Imagination
- 145. World Models
- 146. DayDreamer
- 147. Mastering Atari with Discrete World Models
- 148. Dreamer V3: Mastering Diverse Domains through World Models
- 149. Transformers are Sample-Efficient World Models
- 150. TWM: Transformer-based World Models
- 151. 1X World Model Challenge
- 152. Cosmos World Foundation Model Platform
- 153. GAIA-1
- 154. Genie: Generative Interactive Environments
- 155. Navigation World Models
- 156. UniSim