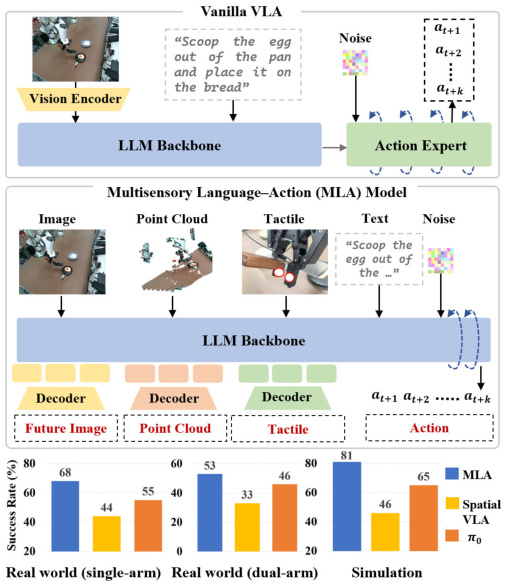
MLA: Multisensory Language-Action Model
这是给读者写的"零术语"版本。任何新词第一次出现都会用一句话+生活类比讲清楚。
一句话讲什么(TL;DR)
让机器人不只用眼睛看,还会用"手感"和"空间感",并且提前猜下一秒发生什么再动手。
所以这一节是想说:MLA 给机器人加了"手感"和"空间感",还会"脑补未来"。
这是个什么场景
想象一下:你拿着湿布擦黑板。眼睛盯着哪里还有粉笔字;手腕在感受压得紧不紧——压太轻擦不掉,压太重又会"吱啦"一声把黑板划花;胳膊在感受布有没有真贴在板上。这三件事你是同时在做的,根本没在脑子里分开想。
现在换个玩法:让你戴上 VR 头盔,远程操作一只机械手去擦——你只能"看",没有手感、没有距离感。结果就是擦个黑板都跟拆炸弹一样紧张。
机器人今天就处在这个尴尬位置。它过去主要靠摄像头(相当于只有眼睛),可现实里很多活——擦桌、盖图章、用铲子把鸡蛋铲到面包上——光看是不够的,得眼睛、距离感、指尖三样一起配合才不会出岔子。
接触密集任务(contact-rich task):机器人要反复碰到物体、还要施力的活儿。比如擦、按、铲、压。
所以这一节是想说:擦黑板这种"用力气"的事,光看摄像头办不到,得有手感和距离感。

之前的人怎么做的,为什么不够好
研究者过去的做法存在几个毛病:
- 只让机器人看摄像头,不给手感。就像戴 VR 远程擦黑板,光有视觉,擦不干净。
- 要加新感官,就外挂一个新的"翻译机"。每加一种感官(点云、触觉),就要装一个专门的小程序把这种感官的信号翻译成大脑听得懂的语言。多请一个翻译,多一道损耗,开会效率反而下降。
- 这个"翻译机"没和大脑一起练过。大脑(语言模型)是从读海量书学出来的,外挂翻译是另外学的——两边的"语言体系"对不上。
- 就算它会"想象未来",也只能想象下一张图片。但机器人真正想知道的是"我手按下去会有多紧""那个东西的形状是怎样的"——只想象图像不够。
语言模型(LLM, Large Language Model):吃过海量文字的"大脑",现在的 ChatGPT 内核就是这种东西。MLA 用的是其中一款叫 LLaMA-2。
VLA(Vision-Language-Action 模型):让大脑既能看图、又能听话、又能控制机器人手脚的一类系统。这是 MLA 之前的主流做法。
所以这一节是想说:以前要么感官太少,要么外挂太多,要么只会脑补图片不够立体。
这篇论文的新想法
不要请翻译,让大脑自己直接听三种感官;并且让大脑同时脑补未来的画面、形状和触感,这样它再决定怎么动手会更稳。
所以这一节是想说:把"感知"和"预判"都塞回大脑里,外挂越少越好。
它分几步做的(方法)
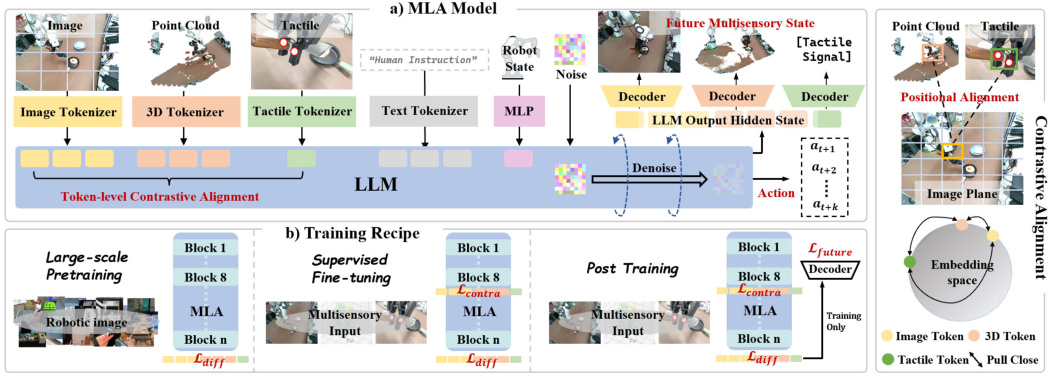
1. 把三种感官直接塞进大脑
类比:原来你请了三个翻译(英语、法语、西语翻译)开会,开口都得绕一圈。现在你直接找一个本身会三种语言的人来听,省去全部翻译。
它在干什么:MLA 不再外挂"图像翻译机""3D 翻译机""触觉翻译机"。它把三种感官的信号都简单切碎,直接送进大脑。大脑前面几层就充当"感知层"。
图像切碎:把一张图片切成 14 像素 × 14 像素的小方格(一共 256 个方格)。每个方格变成一段大脑能理解的"信号"。
点云(point cloud):用激光或深度摄像头测出来的一堆三维坐标点。可以想象成把场景洒满"标记小圆点",每个点都知道自己在空间里的 (x, y, z)。
触觉信号:夹爪指尖的小传感器,能测出"垂直按下去的力""左右的摩擦力""摩擦的方向"。每个指尖输出 6 个数字。
为什么这步有用:
- 少装一套翻译机,省内存、省算力,跑得更快。
- 大脑的"理解空间"是它自己学出来的,外挂的东西永远是"敲门客人",让大脑自己直接听等于"开门让人进客厅",效果更紧密。
所以这一节是想说:感官信号直接交给大脑前几层处理,省掉中间商。
2. 强迫大脑认识到"这同一个东西"
类比:班级合影里有 30 个人,老师指着一张人脸说"这是张三"。你看一眼就能在另一张运动会照片里把张三认出来——因为你知道"同一个人"。但机器原本不知道:图像里的某像素 = 点云里的某 3D 点 = 触觉传感的某接触位置。得有人手把手教它。
它在干什么:在大脑工作的中段(比较靠前的一层),加一个小考试。
等等,先慢一拍——大脑里说的"信号"是什么? 大脑在处理任何东西的时候,都会把它压成一串数字(数学上叫"向量")。下面说"两个信号长得像",本质就是两串数字的方向接近。明白了这一点再看考试规则:
- 给一个三维点(点云里的小圆点),用相机的几何参数算出它落在图片里的哪个 14×14 小方格里。这一步是纯几何,不用学习——就像你知道"教室前排第三个座位"在班级合影里的哪个位置一样。
- 这个 3D 点的"信号"和那个小方格的"信号"应该长得很像(在数学上"夹角小")。
- 这个 3D 点的"信号"和其他 255 个小方格的"信号"应该长得不像。
- 触觉同理:夹爪在场景里的位置投到图像哪个小方格,那块小方格就是触觉的"伴侣"。
向量长得像:高中学过两个向量的"夹角"。夹角越小,两个向量越像。这里就是用同一招——让"对应的两个信号向量"夹角小,"不对应的"夹角大。
扣分项(loss):模型学习的目标。可以理解成考试扣分总和——越小越好。模型学习就是想办法降低这个扣分。
对比扣分(contrastive loss):扣分规则是"对的拉近、错的推远"。对就少扣,错就多扣。
为什么这步有用:
- 用几何代替猜测:什么叫"图像里的猫和点云里的猫是同一个猫"?这很难定义。但"3D 点 (x,y,z) 投影到像素 (u,v)" 是几何算出来的、确定的事。论文聪明的地方就是用几何当老师。
- 加在中段而不是末段:大脑前几层还在认东西,最后几层在做决策。在中段加考试最合适——既学到位,又不挤掉决策的容量。
所以这一节是想说:用几何把三种感官"对齐成同一件事",让大脑知道它们说的是一个东西。
3. 让大脑脑补"下一秒"会发生什么
类比:打篮球抢板,你不会等球落下来才举手——你会预判球会弹到哪里然后提前到位。机器人也一样:与其每一帧重新看一次,不如让它脑补"几秒后场景会变成什么样",提前准备动作。
它在干什么:训练时,让大脑除了输出动作,还要同时回答三个题:
- "几秒后这个场景的图片应该长什么样?"
- "几秒后这个场景的 3D 形状应该是什么样?"
- "几秒后我的指尖会感受到什么力度?"
但这三个题只在训练阶段考——机器人真正干活时不考,省得拖速度。
关键帧:动作的"转折时刻"——比如夹爪从张开变合上的那一帧、机器手从快速移动变成慢速接触的那一帧。一段 200 帧的视频里关键帧通常只有 5-15 帧。预测关键帧比预测下一帧更有挑战,模型也学得更深。
脑补图像怎么扣分:让模型猜出来的图片和真的图片每个像素一一对比,差距越大扣分越多。但这里有个小技巧——背景部分不计扣分,只算前景物体,省得模型把功夫花在没用的桌子布纹上。
为什么这步有用:
- 三种感官都让大脑去预测,大脑就被迫把"图像、空间、触感"这三类信息同时编码进自己的中间状态。这个中间状态再去指挥动作,自然更稳。
- 训练时多做几道题,但真打比赛时这几道题不考——好处全拿,代价不交。
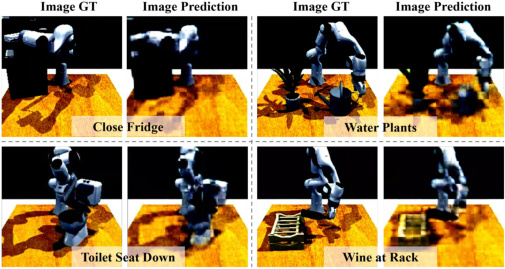
(左边是真实未来画面,右边是 MLA 脑补出来的——可以看到机械臂的姿势、物体的状态都被合理地猜出来了。)
所以这一节是想说:训练时多让大脑做"预判题",干活时省掉这部分,相当于白嫖了一波理解力。
4. 训练分三阶段,像婴儿学走路
类比:婴儿先学说话和认人脸,再学摸东西的手感,最后学会预判球会飞到哪里。一口气全教会教不来。
它在干什么:把整个训练拆成三个阶段,每段加点新东西。
| 阶段 | 数据规模 | 这一阶段教什么 |
|---|---|---|
| 1. 大基础训练 | 57 万段视频、3600 万张画面 | 只教"看图 + 听话 + 出动作"。点云和触觉的位置先空着。 |
| 2. 专项训练 | 6 个真机任务,每任务 200 段示范 | 加入点云、触觉,开始练"对齐三种感官"。 |
| 3. 加预判题 | 同上 | 在专项训练之上,再加"脑补未来"的扣分项。 |
为什么不能一锅炖:网上能找到的开源机器人数据,几乎都没有触觉、没有点云。如果一开始就把触觉位置塞进去,模型会被空数据带偏。先用海量"看图听话"打底,再逐步加新感官,更稳。
所以这一节是想说:分阶段教,像教小孩一样,先打底再加难度。
5. 用"画家擦噪点"的方式输出动作
类比:素描班老师让你先在白纸上随意涂一团乱线,然后一遍遍擦、修,最后浮现出一只猫的轮廓。MLA 输出动作的方式就是这样——先给一团乱数字,再迭代几步擦干净,最后变成机器人手要走的精确路径。
它在干什么:动作不是一步算出来的,而是迭代擦出来的。
- 训练时:把真实动作(一组 7 个数字:手要往哪个方向移动多少 + 怎么转 + 夹爪开多大)人工加上随机噪声,让模型学着把噪声去掉。
- 干活时:从纯噪声开始,迭代 4 步擦干净,得到最终动作。
扩散模型(diffusion):就是这种"先加噪再擦干净"的套路。你日常用的 AI 画图(Midjourney、Stable Diffusion)也是这套,只不过它擦的是图片,MLA 擦的是动作。
为什么不直接算一步出动作:因为同一个场景下经常有"好几种合理动作"——比如把杯子拿起来,左手拿、右手拿都行。直接一步算会被模型平均成一个"中间值",那个中间值往往不能执行。扩散模型天然能处理"多种合理选项"。
所以这一节是想说:动作输出像素描,先乱画再修,避免被"平均值"坑。
关键数字(What works)
每个数字都按"实验是怎么做的 → 结果 → 跟谁比 → 这意味着什么"读。
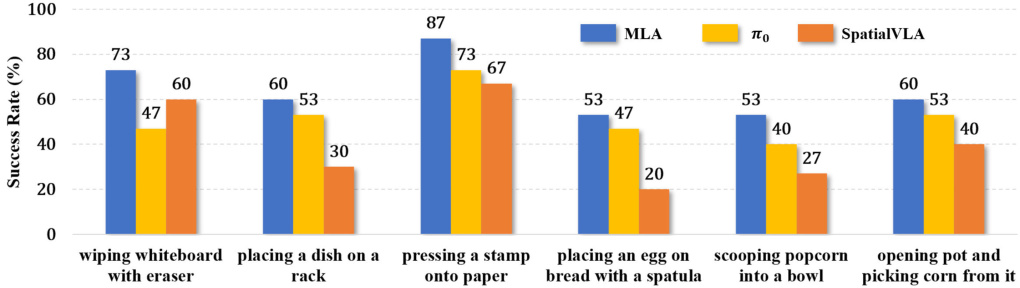
真机 6 个任务平均成功率领先 12 个百分点
- 设置:每任务 200 段示范训练,每个测 15 次,桌面物体起始位置随机。
- 跟谁比:上届最强的"只看图"系统(叫 π₀,2024 年 SOTA)。
- 意义:相当于上届冠军考了 70 分,新手考了 82 分——差距很大。
真机比 3D 老牌选手多赢 24 个百分点
- 跟谁比:专门为 3D 设计的另一种系统(SpatialVLA,2025 年)。
- 意义:那家专门请了 3D 翻译,反而打不过 MLA 这个"不请翻译"的,说明加翻译不一定有用。
仿真器里 10 个标准任务平均 81%
- 设置:在电脑模拟器里跑(没有真触觉,因为仿真不够真实)。
- 结果:MLA 81% 领先第二名 16 个百分点。
- 意义:就算砍掉触觉,靠"对齐 + 预判"两个核心想法本身也站得住,不是单靠多一个传感器赢的。
换没见过的物体,掉的分更少
- 设置:训练时用鸡蛋,测试改成生菜;训练时桌面干净,测试桌面堆杂物。
- 结果:老办法掉 26%-47%,MLA 只掉 15%-25%。
- 意义:从"实验室能跑"到"客户家也能跑"的一大步。换个新场景能不能扛住,是机器人能否真上线的关键。
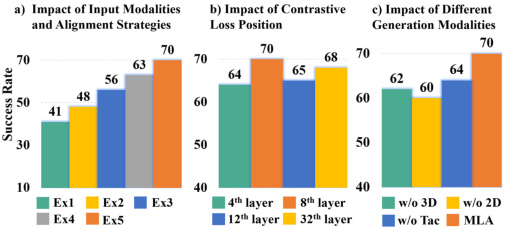
对比扣分加在大脑哪一层最好?第 8 层
- 设置:大脑共 32 层,分别试在第 4、8、12、32 层上加这个考试。
- 结果:第 8 层最好,第 32 层最差。
- 意义:太前面(第 4 层)信号还没成型;太后面(第 32 层)已经在准备出动作了,再加考试会"分裂人格"。第 8 层是"刚成型还没决策"的甜区。
多请一个翻译反而掉 7 个百分点
- 设置:在 MLA 上额外加装 SigLIP(Google 开源的图文翻译机)和 Lift3D(3D 翻译机)。
- 结果:性能掉 7%。
- 意义:少请翻译不是只省钱——它本身就让模型学得更好。"加料"反而是坑。
所以这一节是想说:MLA 的赢面不是靠堆硬件,是靠"少装翻译 + 对齐三感官 + 预判未来"这套思路。
你应该懂的几个新词
- VLA(Vision-Language-Action 视觉-语言-动作模型):让一个吃过海量文字图片的大脑,去控制机器人手脚的系统。类比:"一个会聊天的人,被装上手和身体后开始干活"。
- 大语言模型(LLM):吃过海量文字训练出来的"大脑"。类比:ChatGPT 的内核就是这种东西。
- 接触密集任务(contact-rich task):机器人要反复接触物体并施力的活。类比:擦、按、压、铲都算。
- 点云(point cloud):用深度摄像头测出来的一堆三维坐标点。类比:把场景洒满"标记小圆点",每个点知道自己的 (x,y,z)。
- 扣分(loss):考试扣分总和——越小越好。模型学习就是想办法降低它。
- 对比扣分(contrastive loss):扣分规则是"对的拉近、错的推远"。
- 关键帧(keyframe):动作的"转折时刻",比如夹爪从开变合的那一帧。类比:看连环画时只看转折页,不看每一格都差不多的连续页。
- 扩散模型(diffusion model):先加噪声再擦干净的输出方式。类比:素描——先乱涂再修。
- 末端执行器(end-effector):机器人手最末端会接触物体的部分,通常是夹爪。
- 自由度(DoF, Degrees of Freedom):能独立控制的轴数。单臂 7 个自由度 = 3 个移动方向 + 3 个旋转方向 + 1 个夹爪开合。
- 最远点采样(FPS, Farthest Point Sampling):从一堆点云里挑出几个"互相离得最远"的点当代表。类比:从全班同学里挑 5 个身高差异最大的人代表全班。
- K 近邻(KNN):给一个点找它周围最近的 K 个朋友。类比:你在班里的 K 个最好朋友。
所以这一节是想说:把这 12 个词记住,再读其他机器人论文就不会被生词卡住。
它有什么搞不定的
- 极端场景换得太狠还是会跪:背景大改时 MLA 还是掉 25%。如果客户家光线、桌面颜色和实验室差太远,成功率可能腰斩。
- 触觉传感器一坏就废:论文没测"传感器损坏 / 噪声大"的情况。一个夹爪坏一颗触觉,那几个任务可能直接挂掉。
- 关键帧检测靠"速度变化":如果你的任务是缓慢精细操作(比如缓慢倒酒、写字),速度变化平滑,关键帧会找不准。
- 没换过语言指令:泛化实验只换了物体和背景,"把鸡蛋放到面包上"这句话从没换过。换成"把鸡蛋放到吐司上"它能不能听懂?没测。
- 只在一种机械臂上训练和测试:换成另一种机械臂能不能直接跑?没测。这是这条线整体的共同问题。
- 代码和自采数据论文没承诺开源:想完全复现得自己采那 200 段示范 × 6 个任务,门槛很高。
- 训练费用没透明:论文不告诉你要烧多少卡时、用了多少张显卡。粗估光训练成本就 5-20 万人民币。
所以这一节是想说:方法漂亮,但离普通人买回家用还远——硬件贵、环境敏感、复现门槛高。
它和别的几篇是什么关系
可以画成一个集合关系:
- VLA 主线(OpenVLA、π₀):只看图 + 听话 + 出动作。MLA 在这条线上加了点云和触觉两个"新感官"。
- 3D 路线(SpatialVLA):选了"加专门 3D 翻译机"的相反路线。MLA 反过来——砍掉翻译机用对齐学习。两者给"3D 怎么进 VLA"的相反答案。MLA 在仿真里赢 SpatialVLA 35 个百分点。
- 未来预测派(DreamVLA、CoT-VLA、UP-VLA):让模型脑补下一秒。但他们只脑补图片。MLA 把脑补扩展到点云和触觉。
- 技术依赖:关键帧检测和点云分组方式直接借自 Lift3D 这篇前作。
时间线上:
2024 ━━ OpenVLA (开源 baseline)
2024 ━━ π₀ (2D SOTA)
2025 ━━ SpatialVLA (3D 路线)
2025 ━━ DreamVLA (未来预测派)
2025 ━━ MLA (合并多感官 + 未来预测)
所以这一节是想说:MLA 是把"多感官"和"未来预测"两条支线合并的工作,站在好几位前辈肩膀上。
我建议这样读这篇
- 先看摘要 + 第一张图(img_000.jpg) — 10 分钟搞清楚它要干嘛、和老办法差在哪。
- 盯着第二张图(img_003.jpg)看 5 分钟 — 这张图是论文的"地图",三个感官在哪、考试加在哪、预判分支挂在哪,全在这一张。
- 回到本笔记的"方法第 1-3 步" — 这是核心创新,弄懂这三步后面就顺。
- 跳到结果图(img_004.jpg)和消融图(img_006.jpg) — 直接看条形图比读文字快。
- 最后扫一眼实验细节 — 任务怎么设的、用的什么硬件,做出"我能不能复现"的判断。
- 如果时间紧,跳过:仿真实验细节、附录数据集列表(除非你要复现)。
所以这一节是想说:先看图后看字,从全局再到细节,少走弯路。
一些好奇心问答(FAQ)
Q1:模型多大?我家电脑跑得动吗?
- 模型主体大约 70 亿个参数(业界叫 7B)。光是模型权重就要 14 GB 显存。训练至少要 4-8 张专业显卡(每张 80 GB 那种)。推理理论上需要一张 24 GB 高端卡(比如 RTX 4090 紧巴巴)。普通笔记本(如 RTX 4070 12GB)跑不动。
Q2:训练数据从哪来?
- 大基础阶段:用网上公开的开源数据集合并(57 万段视频、3600 万张画面),不需要授权。
- 专项阶段:作者自己用一套叫 Gello 的"远程操作系统"采的 6 个任务、共 1200 段示范。这部分没承诺开源。
Q3:为什么不用更简单的办法,比如直接给机器人写规则?
- 因为机器人要做的事太多变。"擦黑板"涉及的角度、力度、位置随场景千变万化,写规则要写到天荒地老。让模型自己从示范里学是更通用的办法。
Q4:触觉传感器是什么?贵吗?
- 论文用的是一种叫 Tashan TS-E-A 的传感器,每个夹爪指尖装一个,能测 6 个力的数字。单个传感器几千块人民币。配套的 Franka 机械臂大约 25-35 万。整套硬件不是个人玩家能负担的。
Q5:为什么训练要分三个阶段,一锅炖不行吗?
- 因为公开数据里只有图像和动作,没有触觉和点云。一开始就要求模型同时处理三种感官,它会被"空数据"带偏。先用海量看图听话打底,再逐步加新感官,稳定得多。
Q6:跑一次推理要多久?机器人能跟上人的反应吗?
- 论文没公开具体数字。粗估 5-10 Hz(每秒 5-10 次决策),够慢操作用,做不了像羽毛球这种快速反应的事。
Q7:第 8 层为什么是甜区,是数学算出来的吗?
- 不是,是消融"凑出来的"——试了第 4 / 8 / 12 / 32 层,第 8 层最好。论文没给理论解释。换到别的大脑模型上还成不成立,要重新试。
Q8:这套方法以后能用在自动驾驶里吗?
- 思路(多感官融合 + 预判未来)是通用的。但 MLA 现在只在一种机械臂上验证过,搬到汽车上还要重新训。特斯拉 FSD 走的是相邻的另一条路——只用摄像头不要 3D。
所以这一节是想说:硬件贵、显卡费、训练慢,但思路本身值得借鉴。
如果你想再深入
按"必读 → 续作 → 竞争"的顺序:
- π₀(2024):MLA 反复对比的"前任冠军"。读它能让你理解"没有 3D 和触觉时机器人能做到什么"。
- OpenVLA(2024):开源代码量最大的同类系统。如果你想动手跑,先跑 OpenVLA 比直接复现 MLA 容易十倍。
- SpatialVLA(2025):走"加 3D 翻译机"的相反路线。读它能看清两种 3D 思路的优缺点。
- DreamVLA(2025):纯做未来预测的同期工作。MLA 在仿真里赢它 16 个百分点,对比读能看出"预测点云和触觉"为什么有用。
- Lift3D Policy(2025):MLA 的关键帧检测和点云分组直接借自这篇。想真复现 MLA,这篇是绕不过去的依赖。
如果你只能读 1 篇,挑 π₀ —— 它是这条线的"标尺"。
所以这一节是想说:想深入这条线,5 篇就够了;想动手,先从 OpenVLA 开始。
◼
引用本笔记 / Cite this note
@online{eai_mla_2026,
title = {(readable note) MLA: Multisensory Language-Action Model},
author = {Zhou, Jason},
year = {2026},
note = {Note on a 2024 paper},
howpublished = {\url{https://estelledc.github.io/embodied-ai-reading-station/papers/mla/}},
organization = {Embodied AI Reading Station}
}
All 156 papers (full index)
- 1. LLaVA: Visual Instruction Tuning
- 2. 3DShape2VecSet: 3D Shape Representation for Diffusion Models
- 3. SayCan: Do As I Can, Not As I Say
- 4. OpenVLA: An Open-Source Vision-Language-Action Model
- 5. VLAS: VLA Model With Speech Instructions
- 6. MLA: Multisensory Language-Action Model
- 7. Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control
- 8. CartoRadar: RF-Based 3D SLAM Rivaling Vision Approaches
- 9. mmCLIP: Boosting mmWave-based Zero-shot HAR via Signal-Text Alignment
- 10. mmNorm: Non-Line-of-Sight 3D Object Reconstruction via mmWave Surface Normal Estimation
- 11. Proactive Hearing Assistants that Isolate Egocentric Conversations
- 12. NeuralAids: Wireless Hearables With Programmable Speech AI Accelerators
- 13. Creating speech zones with self-distributing acoustic swarms
- 14. Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation
- 15. SoundStream: An End-to-End Neural Audio Codec
- 16. AudioLM
- 17. Conformer
- 18. Dual-path RNN
- 19. EnCodec
- 20. Meta-StyleSpeech
- 21. MusicLM
- 22. Robust Speech Recognition via Large-Scale Weak Supervision
- 23. SeamlessM4T
- 24. Stable Audio
- 25. Universal Source Separation with Weakly Labelled Data
- 26. Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning
- 27. RLBench: The Robot Learning Benchmark & Learning Environment
- 28. robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
- 29. BridgeData V2
- 30. CALVIN
- 31. LIBERO
- 32. RH20T
- 33. What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
- 34. DROID
- 35. Open X-Embodiment
- 36. RoboCasa
- 37. SimplerEnv
- 38. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
- 39. 3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
- 40. Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation
- 41. EquiBot: SIM(3)-Equivariant Diffusion Policy
- 42. DiT-Policy
- 43. Diffusion Policy Policy Optimization (DPPO)
- 44. Affordance-based Robot Manipulation with Flow Matching
- 45. FlowPolicy: 3D Flow-based Policy via Consistency Flow Matching
- 46. FAST: Efficient Action Tokenization for VLA
- 47. pi_0: Vision-Language-Action Flow Model
- 48. pi_0.5: VLA with Open-World Generalization
- 49. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
- 50. Generative Adversarial Imitation Learning
- 51. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (ACT/ALOHA)
- 52. AnyTeleop
- 53. Behavior Transformers: Cloning k Modes with One Stone
- 54. Implicit Behavioral Cloning
- 55. RoboCat
- 56. ALOHA 2
- 57. DexCap
- 58. HumanPlus
- 59. Generalizable Humanoid Manipulation with 3D Diffusion Policies (iDP3)
- 60. Mobile ALOHA
- 61. SmolVLA
- 62. Universal Manipulation Interface
- 63. Behavior Generation with Latent Actions (VQ-BeT)
- 64. ImageBind: One Embedding Space To Bind Them All
- 65. Connecting Touch and Vision via Cross-Modal Prediction
- 66. AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
- 67. AudioPaLM
- 68. FROMAGe: Grounding LLMs to Images
- 69. OneLLM
- 70. X-VLM: Multi-Grained Vision Language Pre-Training
- 71. Tactile Beyond Pixels (Sparsh-X)
- 72. Sparsh: Self-supervised Touch Representations
- 73. Tactile-VLA
- 74. TLA: Tactile-Language-Action
- 75. Code as Policies: Language Model Programs for Embodied Control
- 76. Inner Monologue: Embodied Reasoning through Planning with Language Models
- 77. LLM+P: Empowering LLMs with Optimal Planning
- 78. PaLM-E: An Embodied Multimodal Language Model
- 79. ProgPrompt
- 80. ChatGPT for Robotics
- 81. GenSim
- 82. RoboFlamingo
- 83. Tree-Planner
- 84. VoxPoser
- 85. See Through Smoke: Robust Indoor Mapping with Low-cost mmWave Radar
- 86. Can WiFi Estimate Person Pose?
- 87. 3DRIMR: 3D Reconstruction and Imaging via mmWave Radar based on Deep Learning
- 88. milliEgo: Single-chip mmWave Radar Aided Egomotion Estimation via Deep Sensor Fusion
- 89. High Resolution Point Clouds from mmWave Radar
- 90. RadarSLAM: Radar based Large-Scale SLAM in All Weathers
- 91. Through-Wall Pose Imaging in Real-Time with a Many-to-Many Encoder/Decoder Paradigm
- 92. RFMask: A Simple Baseline for Human Silhouette Segmentation with Radio Signals
- 93. RFPose-OT: RF-Based 3D Human Pose Estimation via Optimal Transport Theory
- 94. Argus: Multi-View Egocentric Human Mesh Reconstruction Based on Stripped-Down Wearable mmWave Add-on
- 95. Diffusion Model is a Good Pose Estimator from 3D RF-Vision
- 96. Enabling Visual Recognition at Radio Frequency (PanoRadar)
- 97. Wave-Former: Through-Occlusion 3D Reconstruction via Wireless Shape Completion
- 98. Habitat: A Platform for Embodied AI Research
- 99. Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
- 100. DexMV
- 101. Habitat 2.0
- 102. ManiSkill
- 103. ProcTHOR
- 104. SAPIEN: A SimulAted Part-based Interactive ENvironment
- 105. BEHAVIOR-1K
- 106. Habitat 3.0
- 107. Isaac Lab
- 108. MuJoCo Playground
- 109. RT-1: Robotics Transformer for Real-World Control at Scale
- 110. 3D Diffusion Policy (DP3)
- 111. Octo: An Open-Source Generalist Robot Policy
- 112. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- 113. RT-Trajectory: Robotic Task Generalization via Hindsight Trajectory Sketches
- 114. 3D-VLA
- 115. DexVLA
- 116. GR-2: Generative Video-Language-Action Model
- 117. OpenHelix
- 118. OpenVLA-OFT
- 119. RDT-1B: Diffusion Foundation Model for Bimanual Manipulation
- 120. RoboMamba
- 121. SpatialVLA
- 122. TinyVLA
- 123. TraceVLA: Visual Trace Prompting
- 124. Learning Transferable Visual Models From Natural Language Supervision
- 125. Flamingo: a Visual Language Model for Few-Shot Learning
- 126. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 127. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- 128. DeepSeek-VL: Towards Real-World Vision-Language Understanding
- 129. EVA-CLIP: Improved Training Techniques for CLIP at Scale
- 130. FILIP: Fine-grained Interactive Language-Image Pre-Training
- 131. Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
- 132. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
- 133. Improved Baselines with Visual Instruction Tuning
- 134. OBELICS
- 135. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
- 136. Sigmoid Loss for Language Image Pre-Training
- 137. What matters when building vision-language models?
- 138. Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
- 139. The Llama 3 Herd of Models
- 140. LLaVA-NeXT-Interleave
- 141. LLaVA-OneVision: Easy Visual Task Transfer
- 142. Long-CLIP: Unlocking the Long-Text Capability of CLIP
- 143. Pixtral 12B
- 144. Dream to Control: Learning Behaviors by Latent Imagination
- 145. World Models
- 146. DayDreamer
- 147. Mastering Atari with Discrete World Models
- 148. Dreamer V3: Mastering Diverse Domains through World Models
- 149. Transformers are Sample-Efficient World Models
- 150. TWM: Transformer-based World Models
- 151. 1X World Model Challenge
- 152. Cosmos World Foundation Model Platform
- 153. GAIA-1
- 154. Genie: Generative Interactive Environments
- 155. Navigation World Models
- 156. UniSim