Visual
Instruction
Tuning
视觉指令微调 — 让模型从"看图描述"
变成"看图办事"。
Where this fits.
Why LLaVA matters in the embodied-AI roadmap.
中文
本科生科研任务给了 13 篇论文,覆盖 7 个主题:从 VLM 基座,到 任务规划,再到 端到端 VLA、世界模型、射频与听觉。
LLaVA 是 主题 I(VLM 基座)的开山论文,也是其余主题(OpenVLA / SayCan / Cosmos)默认的视觉接入范式。先读它,等于拿到这条主线的钥匙。
English
The undergraduate research brief lists 13 papers across 7 topics — from VLM foundations to high-level planning, end-to-end VLA, world models, RF perception, and auditory intelligence.
LLaVA opens topic I and quietly becomes the default visual front-end of nearly every later paper in the list. Reading it first hands us the key to the rest of the roadmap.
Why visual
instruction tuning?
为什么需要视觉指令微调?
The visual AI in 2023 was blind to instructions.
2023 年的视觉 AI 听不懂"按指令办事"。
中文 · 三个断层
- 视觉模型(CLIP、检测器)很强,但接口僵硬——一个模型只解一个任务,不能用人话切模式。
- 大语言模型 听得懂人话,但眼盲——只能处理文字。
- 已有多模态模型(BLIP-2、Flamingo)能"看图说话",但没专门用图文指令数据训过,一让它"按指令回答"就退化成"描述图片"。
English · three gaps
- Vision models are powerful but rigid — one task per model, no natural-language switching.
- LLMs understand language but are blind to pixels.
- Existing multimodal models weren't trained on image-text instruction tuples, so they fall back to plain captioning when asked to follow instructions.
The method.
方法
Let GPT-4 cook the recipe; have Vicuna plate the dish.
GPT-4 生成图文指令数据 — 158K 条 conversation / detail / reasoning。
Like translating the photo into a recipe before cooking.
Total 158 K instruction tuples.
A USB-to-Type-C adapter, not a Q-Former.
CLIP + 单层线性投影 + Vicuna — 比 BLIP-2 / Flamingo 简单一个数量级。
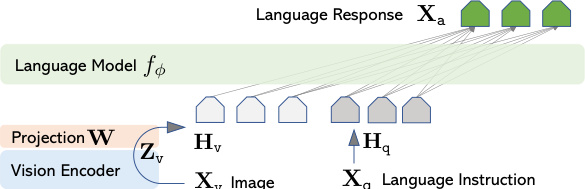
Plate Nº I · LLaVA architecture (Liu et al. 2023, Fig. 1)
CLIP ViT-L/14 把图切成 14×14 patch,输出视觉特征 Z_v。
Projection W(一个矩阵)把 Z_v 投影成"伪词向量" H_v,维度对齐 LLM token embedding。
Vicuna LLM 把 H_v 当成几个特殊词,拼到指令文本前,端到端解码答案。
English: a single-layer projection acts like a USB-to-Type-C adapter — fast to iterate, easy to ablate, surprisingly effective.
Two stages: align, then tune.
先教翻译插头认词,再让整个团队配合演练。
Stage 1 · Feature Alignment Pre-training
- 数据:CC3M 595K 图文对,每张图当成 "describe this image" 的单轮对话
- 训:仅 W;冻结 CLIP 和 LLM
- 类比:先让 USB 转接头学会基本针脚映射
Stage 2 · End-to-End Instruction Tuning
- Data: 158K GPT-4 instruction tuples (conv / detail / reasoning)
- Train: W + Vicuna; CLIP stays frozen
- Analogy: now the whole crew rehearses together
Ablation: skip stage 1 → drop 5.11 pts on ScienceQA. Both stages and model size matter.
Does it work?
实验与结果
Four numbers, one verdict.
Strong instruction following, near-GPT-4 reasoning at 1/100 the data.
"At ~1% the data of contemporaries, the simplest possible adapter outperformed elaborate cross-attention designs. Simplicity wins again."
A bag of patches — not yet a scene.
Where LLaVA still falls short.
中文
- "Patch 袋子"问题:把图当无序 patch,不能精细绑定语义。冰箱里的草莓 + 酸奶会被合并成"草莓味酸奶"。
- 分辨率与百科知识瓶颈:识别拉面店招牌、酸奶品牌之类需要 OCR + 知识库的问题做不好。
- 数据由 GPT-4 自动生成:质量上限被老师模型卡住,会继承 GPT-4 的偏见与幻觉。
- 评测自循环:用 GPT-4 当 LLaVA 输出的裁判,可能偏好 GPT-4 风格答案。
English
- Bag-of-patches: objects co-occurring in patches get fused (yogurt + strawberry → "strawberry yogurt").
- Resolution & world-knowledge ceiling: fails on OCR-heavy or brand-recognition queries.
- Teacher-model ceiling: GPT-4 generated data inherits its biases and hallucinations.
- Self-evaluating loop: GPT-4 grading GPT-4-style answers risks systematic preference bias.
Quietly the visual front-end of every VLA that followed.
悄然成为后续所有 VLA 模型的视觉接入层。
下游影响 · downstream
- OpenVLA / RT-2 / π0 都复用 "CLIP + 投影层 + LLM" 范式(投影层从单层 MLP 升级到 2-layer,核心思路一致)
- SayCan / PaLM-E 把 LLaVA 视觉 token 化方案当作 embodied reasoning 的简化替代
方法论遗产 · methodology
- "用强模型造指令数据"(symbolic data generation)成为多模态训练的标配——RT-2、OpenVLA cotraining 数据都有它的影子
- 极简优于复杂(simplicity wins)成为后续 VLM 设计准则
From reading to doing.
Task 2 路线图 — 把读到的东西在仿真里跑起来。
已完成 · done
- 13 篇论文资料就位(10 篇带图 md + 1 篇网页 + 3 篇 stub)
- 13 篇机器辅助生成的中文 auto-summary 笔记
- 静态学习站(atelier-zero 风格 · GitHub Pages 部署中)
- LLaVA 精读 · 本汇报
下一步 · next
- Reading: SayCan → OpenVLA, then the multimodal & world-model branches
- Coding (Task 2): reproduce
VLM_Grasp_Interactivein mujoco - VLA fine-tune: SmolVLA on LeRobot data, deploy in sim
- Catch up with advisor (张瑞杰 / 王宁) every 2 weeks
Questions, doubts, redirections — welcome.
欢迎追问、纠错、改方向。
presentation deck typeset in Inter Tight + Playfair Display + JetBrains Mono